论文阅读(3)——技术报告
Skywork Open Reasoner 1 Technical Report
本文介绍了 Skywork-OR1,这是一个旨在增强大型语言模型(LLM)推理能力,特别是长链式思考(CoT)模型的强化学习(RL)实现。该工作基于 DeepSeek-R1-Distill 模型系列,通过一系列优化策略显著提升了模型在数学和编码基准测试上的性能。
Skywork-OR1 及其 MAGIC 框架在以下几个方面体现了创新性:
针对长 CoT 模型的 RL 优化: 报告明确指出,许多现有工作侧重于基础模型,而 Skywork-OR1 专注于为已进行监督微调的长链式思考(CoT)模型提供高效且可扩展的 RL 方案,解决了这一特定领域的挑战。
MAGIC 框架的系统性整合与优化:
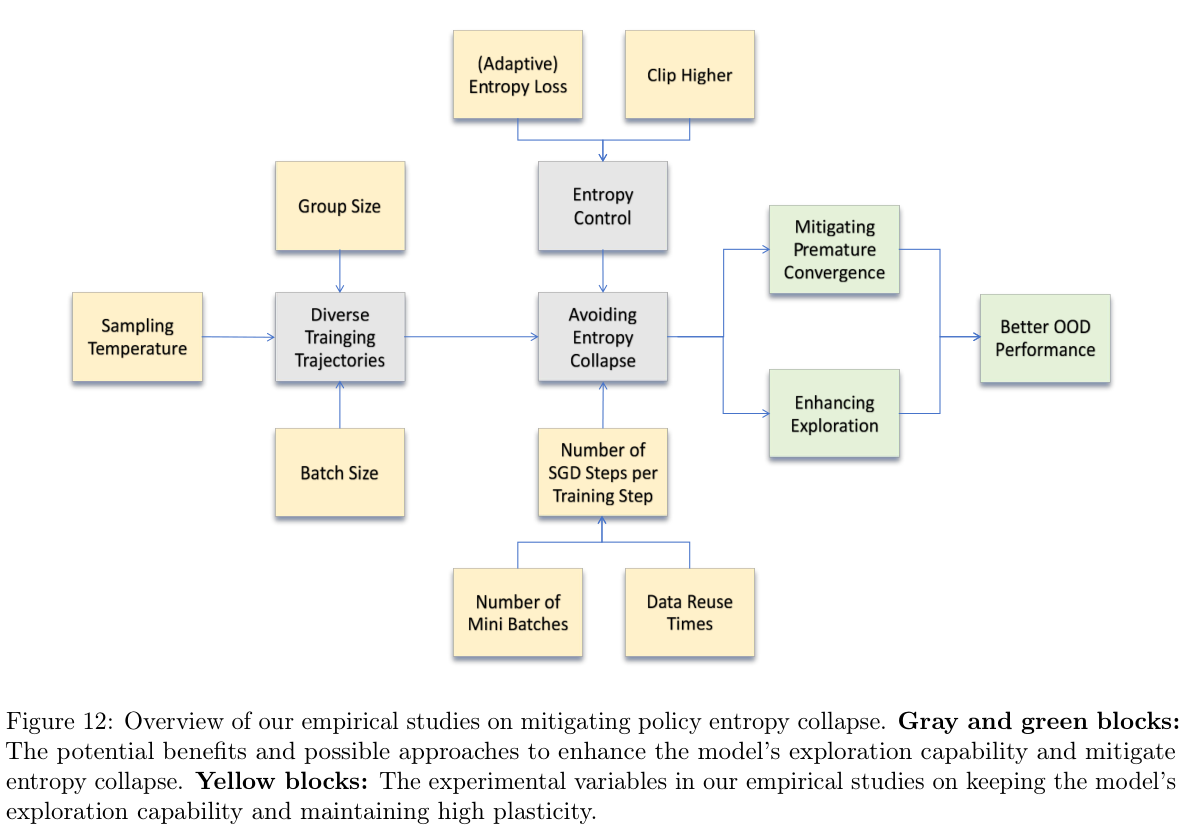
多阶段训练: 创新性地在长 CoT 模型训练中引入多阶段训练,通过在早期阶段使用较短的上下文长度,显著提高了训练效率,同时在后期阶段保持了扩展能力。
自适应熵控制: 针对熵损失系数对训练敏感的问题,提出了动态调整熵损失系数的自适应熵控制机制,确保模型在整个训练过程中保持合理的探索能力和学习可塑性,有效防止了过早的熵衰减。
省略 KL 损失: 经验性地发现 KL 损失在多阶段训练的后期会阻碍性能提升,因此在最终方案中将其省略,这与一些传统 RL 方法有所不同。
在线策略更新的强调: 通过详尽的消融实验,明确指出在线策略更新能够显著减缓熵衰减,并带来更高的测试性能,这为 RL 训练中的策略更新选择提供了重要指导。
高温采样的应用: 发现使用较高的采样温度(例如 1.0)有助于提高模型的初始熵和学习信号,从而在早期阶段增强学习并保留更大的持续训练潜力。
数据处理的精细化: 报告详细阐述了严格的数据源选择、预处理(包括重新提取答案、去除不完整/不相关问题)以及结合人工和 LLM(如 Llama-3.3-70B-Instruct 和 Qwen2.5-72B-Instruct)进行质量评估的方法,确保了训练数据的质量和挑战性。
对熵衰减现象的深入实证分析: 报告不仅识别了熵衰减是影响性能的关键因素,还通过大量消融实验系统地分析了影响熵动态的各种超参数和组件(如采样温度、批次大小、SGD 步数等),并提供了缓解策略,为未来的 RL 研究提供了宝贵的经验见解。
代码沙盒的改进: 在代码验证方面,构建了高效安全的本地代码沙盒,并加入了语法验证、内存监控和并行稳定性优化等措施,提高了验证的准确性和鲁棒性。
Qwen3 Technical Report
Qwen3 包含一系列大型语言模型(LLMs),旨在提升性能、效率和多语言能力。包括:密集型和混合专家(MoE)架构的模型。
Qwen3的创新在于:
1.将思维模式(用于复杂、多步骤推理)和非思维模式(用于快速、上下文驱动的响应)整合到一个统一的框架中,消除了再不同模型之间切换的需要,并能够根据用户查询或聊天模板动态切换模式
2.引入了思维预算机制,允许用户在推理过程中自适应地分配计算资源,从而根据任务复杂性平衡延迟和性能
3.利用旗舰模型的知识,显著降低了构建小规模模型所需的计算资源,同时确保它们具有高度竞争力
Qwen3的预训练过程有三个阶段:
1.通用阶段(S1):模型在约 30 万亿令牌上进行训练,以建立扎实的通用知识基础
2.推理阶段(S2):它在知识密集型数据上进一步训练,以增强在科学、技术、工程和数学 (STEM) 以及编码等领域的推理能力
3.长上下文阶段:模型在长上下文数据上进行训练,以将其最大上下文长度从 4,096 令牌增加到 32,768 令牌
Qwen3的后训练有两个核心目标:
1.思维控制:这涉及整合两种不同的模式,即“非思维”和“思维”模式,为用户提供灵活性,可以选择模型是否进行推理,并通过指定思维过程的令牌预算来控制思维深度。
2.强到弱蒸馏:这旨在简化和优化轻量级模型的后训练过程。通过利用大规模模型的知识,我们大幅降低了构建小规模模型所需的计算成本和开发工作。
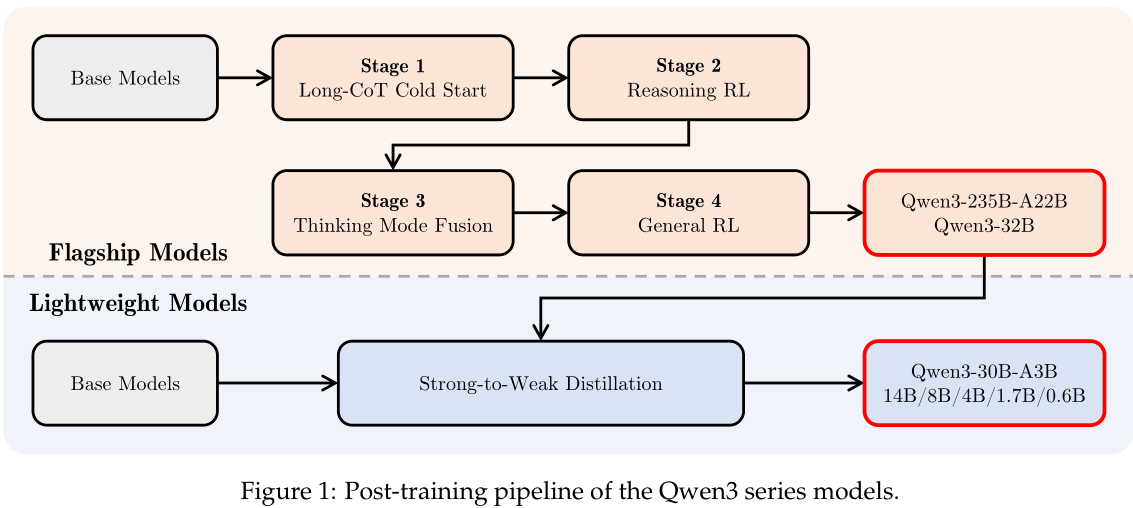
如图 1 所示,Qwen3 系列中的旗舰模型遵循一个复杂的四阶段训练过程。前两个阶段侧重于开发模型的“思维”能力。接下来的两个阶段旨在将强大的“非思维”功能集成到模型中。
1.长思维链冷启动
首先整理一个数据集(涵盖数学、代码、逻辑推理和STEM),每个问题有经过验证的参考答案或基于代码的测试用例。这是冷启动的基础
数据集的构建遵循:(1)查询过滤;(2)响应过滤
然后,将数据集用于推理模式的初始冷启动训练,目的是向模型灌输基础推理模式,而不过分强调及时推理性能
为了在后续RL阶段增加灵活性和改进空间,该阶段需要减少训练样本数量和训练步骤
2.推理强化学习
该阶段使用的查询-验证器必须满足四种标准:(1)未在冷启动阶段使用;(2)对冷启动模型可学习;(3)尽可能具有挑战性;(4)涵盖广泛的子领域
3.思维模式融合
阶段的目标是将“非思维”能力集成到先前开发的“思维”模型中。
为了实现这一目标,我们对推理强化学习模型进行持续的监督微调(SFT),并设计了一个聊天模板来融合这两种模式。
发现能够熟练处理两种模式的模型在不同的思维预算下表现始终如一。
SFT数据的构建:“思维”+“非思维”
聊天模板设计:

思维预算:当模型的思维长度达到用户定义的阈值时,我们手动停止思维过程并插入停止思维指令:“考虑到用户时间有限,我现在必须直接根据思维给出解决方案。\n</think>。\n\n”
4.通用强化学习
该阶段旨在增强模型在不同场景下的能力和稳定性
建立了一个复杂的奖励系统,涵盖 20 多个不同的任务,每个任务都有定制的评分标准。这些任务专门针对以下核心能力的增强:
指令遵循
格式遵循
偏好对齐
代理能力
专业场景能力
为了为上述任务提供反馈,使用了三种不同类型的奖励:
基于规则的奖励:广泛应用于推理RL阶段(对“指令/格式遵循”很有用)
带参考答案的基于模型的奖励:此方法允许更灵活地处理各种任务,而无需严格的格式要求,避免了纯粹基于规则的奖励可能出现的假阴性
不带参考答案的基于模型的奖励:利用人类偏好数据,我们训练一个奖励模型来为模型响应分配标量分数。这种方法不依赖于参考答案,可以处理更广泛的查询,同时有效增强模型的参与度和有用性。
5.强到弱蒸馏:
专门设计用于优化轻量级模型,包括 5 个密集型模型一个 MoE 模型。
这种方法在有效赋予强大的模式切换能力的同时,提高了模型性能。蒸馏过程分为两个主要阶段:
离策略蒸馏:在此初始阶段,我们结合教师模型在
/think和/no think两种模式下生成的输出进行响应蒸馏。这有助于轻量级学生模型发展基本的推理技能和在不同思维模式之间切换的能力,为下一个在策略训练阶段奠定坚实基础。在策略蒸馏:在此阶段,学生模型生成在策略序列进行微调。具体来说,采样提示,学生模型以
/think或/no think模式生成响应。然后,通过将其 logits 与教师模型(Qwen3-32B 或 Qwen3-235B-A22B)的 logits 对齐,以最小化 KL 散度来微调学生模型。
6.后训练评估:
为了全面评估指令微调模型的质量,我们采用了自动基准测试来评估模型在思维和非思维模式下的性能,维度包括:
通用任务
对齐任务
数学与文本推理
代理与编码
多语言任务
在本技术报告中,我们介绍了 Qwen 系列的最新版本 Qwen3。Qwen3 具有思维模式和非思维模式,允许用户动态管理用于复杂思维任务的令牌数量。该模型在包含 36 万亿令牌的广泛数据集上进行了预训练,使其能够理解和生成 119 种语言和方言的文本。通过一系列全面评估,Qwen3 在各种标准基准测试中,无论是预训练模型还是后训练模型,都表现出强大的性能,包括与代码生成、数学、推理和代理相关的任务。
在不久的将来,我们的研究将集中于几个关键领域。我们将继续通过使用更高质量和更多样化内容的数据来扩大预训练规模。同时,我们将致力于改进模型架构和训练方法,以实现有效的压缩、扩展到极长的上下文等目的。此外,我们计划增加强化学习的计算资源,特别强调基于代理的 RL 系统,这些系统从环境反馈中学习。这将使我们能够构建能够解决需要推理时扩展的复杂任务的代理。
Phi-4-reasoning Technical Report
本文介绍了微软基于其原有的Phi-4模型(14B参数)专门针对推理能力进行优化的版本——Phi-4-reasoning,微软还训练了一个增强版本:Phi-4-reasoning-plus,通过强化学习进一步提升了模型的推理能力。
它在数学、科学推理、编程和算法问题解决等领域表现惊人,甚至在某些任务上超越了参数量达70B的DeepSeek-R1-Distill-Llama和其他顶级模型!
这个模型的特点在于以下几个环节:
(1)精心筛选的"可教授"数据集
微软创建了一个高质量的“种子数据库”,其中包含:
位于 Phi-4 当前能力边缘的种子(用弱模型的生成与真实方案的一致性来估计种子难度)
涵盖STEM(科学、技术、工程和数学)、编程等多领域
合成种子数据(比如编码转换为文字问题,或者重写数学问题)
(2)Phi-4-reasoning:Phi-4 的监督微调
Phi-4-reasoning 的架构与 Phi-4 模型相同,但有两个关键修改:
推理令牌: 基础模型中的两个占位符令牌被重新用作
<think>和</think>令牌,分别标记推理(“思考”)块的开始和结束增加令牌长度: 基础模型 (Phi-4) 最初支持最大令牌长度为 16K。为了容纳额外的推理令牌,ROPE [51] 基频加倍,模型训练的最大长度为 32K 令牌。
在模型扩展阶段使用O3-mini作为教师模型
(3)Phi-4-reasoning-plus:在 Phi-4-reasoning 之上进行少量 RL
在SFT后,应用GRPO算法进行强化学习,以增强Phi-4-reasoning模型的推理能力
训练奖励模型
确定GRPO算法目标函数
在GRPO中通过基于响应长的的拒绝采样,通过选择性地调节过于冗长、通常不正确的输出,从而提高模型效率