数据仓库复习整理
【注】:与ai对话的提示词可以在https://github.com/HappynessI/Prompts_For_All_Work/blob/main/System%20Prompt/Review%20for%20exams找到
【注】:资料在:https://pan.baidu.com/s/10YKfym7x2axrRAPAWXLGyw?pwd=1895
第7章 数据挖掘概述
知识发现、数据挖掘
数据挖掘主要功能
数据挖掘过程模型
7.1 知识发现、数据挖掘
【什么是数据库中的知识发现(KDD)】:
KDD 或数据挖掘是一个从数据集中识别出有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程(烹饪大餐的全过程)
有趣性:有效性、新颖性、潜在有用性、最终可理解性的综合
【数据挖掘(DM)】:
数据挖掘是一门综合性技术,受许多学科领域影响,但受数据库、机器学习和数理统计3个领域影响最大
【例题】:

1. 根据性别划分公司的顾客
答案:不是
助教解析:这只是简单的数据库查询(Query)操作(类似于 SQL 中的
SELECT ... WHERE gender = 'F')。性别是数据中显式存在的字段,不需要挖掘“隐含”的模式。
2. 计算公司的总销售额
答案:不是
助教解析:这是联机分析处理(OLAP)或简单的统计计算。虽然它很有用,但它只是对现有数据的累加,没有发现“新颖的知识”或建立“预测模型” 。
3. 按学生的标识号对学生数据库排序
答案:不是
助教解析:这是典型的数据管理操作(Sorting)。排序不会产生任何新知识,只是改变了数据的展示顺序 。
4. 使用历史记录预测某公司未来的股票价格
答案:是
助教解析:这是典型的**趋势分析(Trend Analysis)或预测(Prediction)**任务。PPT 中明确提到“对主要股票的交易价格进行预测”属于趋势分析的应用 。它利用历史数据建立模型,来预测未知的未来值。
5. 监视病人心率的异常变化
答案:是
助教解析:这是**异常检测(Anomaly Detection)**任务。PPT 中提到了异常检测用于识别“显著不同于其他数据的观测值”,并列举了“疾病的不寻常模式”作为应用场景 。
第9章 关联分析
认识关联分析
关联规则算法
关联规则变换
序列模式挖掘
【主要内容】——关联分析相关定义、关联规则核心算法(Apriori/FP-Tree)、关联规则的度量、序列模式挖掘
9.1 关联分析相关定义
要是看不懂下面几个名词建议去看PPT
项目、事务、项集、支持度计数、支持度、频繁项集、关联规则
强规则、候选项集
分类属性、数值属性、量化关联规则、离散化
布尔型关联规则、量化型关联规则;单层关联规则、多层关联规则;单维关联规则、多维关联规则;
9.2 关联规则核心算法
Brute-force方法
Apriori方法
FP-Tree方法
1.Brute-force方法:没什么好说的,计算量太大,不可能考
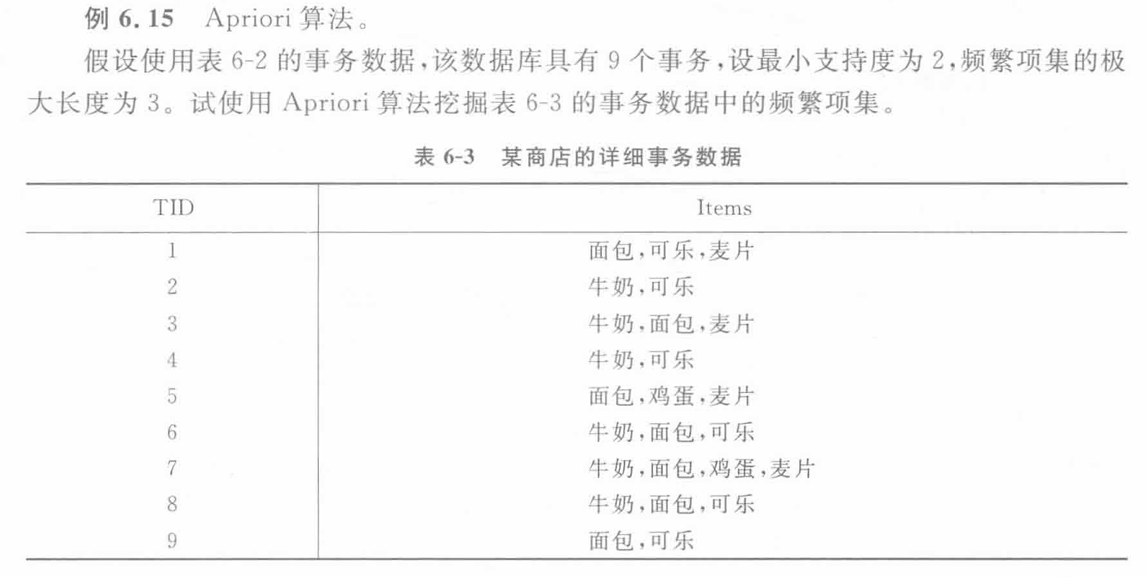
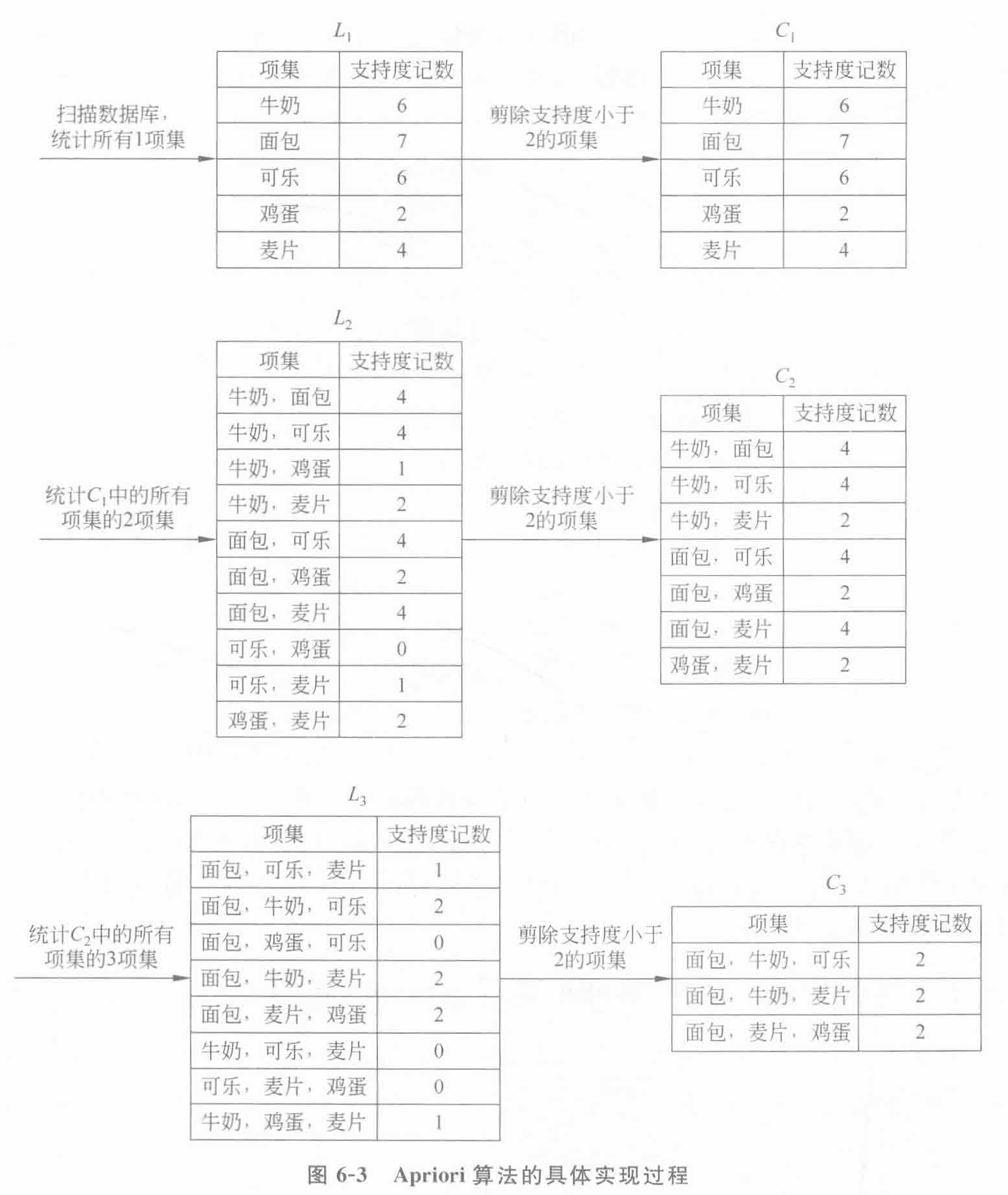
2.Apriori方法:没什么好说的,迭代算法而且得扫描n+1次,做PPT上练习估计一面A4写不下,不太可能考计算
3.FP-Tree方法:往年考过,练习出现过,计算量很小,需要掌握
1.Brute-force方法:
核心思想:把格结构(Lattice Structure)中所有的项集都作为候选项集。将每一个候选项集都去和每一个事务(小票)进行比对,计算支持度。
复杂度:计算复杂度为 O(NMw),其中 N 是事务数,M 是候选项集数量,w 是事务宽度。这个开销非常巨大。如果项目数 d 增加,规则总数呈指数级增长。
2.Apriori方法:
核心原理:
先验原理 (Apriori Principle):如果一个项集是频繁的,则它的所有子集一定也是频繁的;反之,如果一个项集是非频繁的,它的所有超集也一定是非频繁的。利用这个性质进行基于支持度的剪枝 (Support-based pruning)。
工作流程:
策略:广度优先搜索 (Breadth-first search, BFS)。
逐层迭代:先找频繁1-项集,再生成候选2-项集,验证后再生成候选3-项集…。
产生-测试:每次迭代都要生成新的候选项集,然后扫描数据库验证。
缺点 (瓶颈):
产生巨大的候选项集:比如10000个1-项集可能生成 107 个2-项集。
多次扫描数据库:如果最长模式长度为 n,需要扫描 n+1 次数据库。

【例题(参考书)】:计算频繁项集+产生关联规则



3.FP-Tree方法
数据结构:
使用 FP-Tree 将数据库高度压缩 。
FP-Tree 是完备的(包含所有挖掘信息)且紧密的(去除不相关信息) 。
工作流程 (考试常考步骤):
第一次扫描:统计1-项集支持度,排序,过滤非频繁项 。
第二次扫描:构建 FP-Tree 。
挖掘:从头表(Header Table)开始,寻找每个项的条件模式基 (Conditional Pattern Base),递归构建条件 FP-Tree 进行挖掘 。
性能:
通常比 Apriori 快一个数量级 。
只需要扫描数据库 2次

【例题】:

9.3 关联规则的度量
熟悉PPT即可
客观度量:支持度、置信度、提升度、杠杆度、皮尔逊相关系数、IS度量、确信度、卡方、全置信度、极大置信度、K度量
主观度量
9.4 序列模式挖掘
熟悉PPT即可,暂时不知道有没有练习
应用领域:客户购买行为模式预测、Web访问模式预测、疾病诊断、自然灾害预测、DNA序列分析
第10章 分类
分类
决策树
贝叶斯分类
近邻法
支持向量机
人工神经网络
【核心内容】:剪枝、朴素贝叶斯、K-近邻、BP模型、深度学习、Boosting
10.1 分类
评估分类器的方法
分类模型性能评估
10.2 决策树
构造决策树
“最佳”判定属性
剪枝:预剪枝与后剪枝
【部分名词】:(不懂去看PPT)
Gain信息增益(ID3)、Gain Ratio增益率(C4.5)、Gini Index基尼指标;
非监督离散化、监督离散化;
二元属性、标称属性、序数属性;
训练误差、泛化误差;欠拟合、过拟合;
预剪枝、后剪枝(误差降低剪枝REP);
【决策树的例子】:
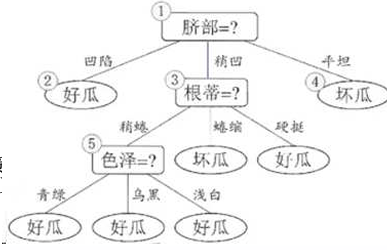
【“最佳”判定属性例题】:


计算量比较大,记住:
信息增益越大越好
增益率越大越好
基尼指数越小越好
ID3、C4.5算法可以多支划分
CART算法只能二分递归,生成二叉树
【误差降低剪枝】:看懂下面这个就行
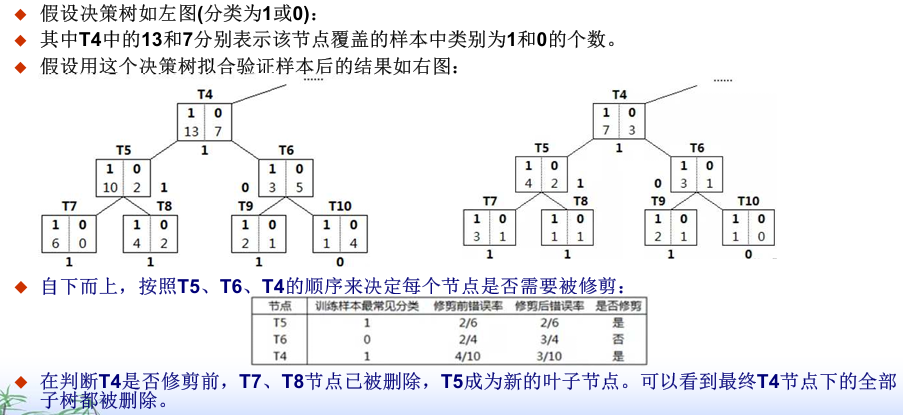
降低误差就删,没有就不删;节点的属性在决策树创建的时候就已经确定好了
10.3 贝叶斯分类
贝叶斯定理
朴素贝叶斯分类
【例题】:


注意统计数量的时候不要出错
10.4 近邻法
KNN算法
从最近邻到K-最近邻
k一般选择奇数,以方便投票表决

可以理解为维护一个元素个数为K的列表(dis_a),B(dis_b),C(dis_c),...],一开始为空,填满K个之后再维护这个列表,小于max_dis的样本替换掉max_dis的样本,直到算完。
【KNN特点】:
懒惰学习:计算量、存储量大,预测慢
K值的选择:一方面要求大一些的K值以减小错误率,一方面要求K个近邻靠近X
K值过大:(如 K=全部):就变成了算总人数,这就变成了谁的数量多就猜谁,完全忽略了局部特征,容易欠拟合
K 太小(如 K=1):容易受噪声影响(如果最近的一个正好是个标错的特例,就分错了),容易过拟合
举例计算:常使用欧式距离(直线距离),需要进行数据归一化
10.5 支持向量机
SVM算法
【核心名词】:
支持向量、函数间隔、几何间隔、间隔边界
线性可分SVM、线性SVM、非线性SVM、硬间隔、软间隔、核技巧
一般来说,一个点距离分离超平面的远近可以表示分类预测的确信程度,越远越确信

【例题】:

有一说一,考试难度估计也就是这样了
找到最近的正负样本对,连接这两个点,做中垂线,一般就是最大间隔分离超平面
(先把(1)(3)式取等号,然后w1=w2得到)
【线性SVM拓展到非线性SVM的方式】:将线性SVM对偶形式中的内积换成核函数
【SVM构造方法】:

【总结】:最大化分类间隔的思想是SVM方法的核心;在SVM决策中其决定作用的是支持向量;少数支持向量避免了“维度灾难”,具有较好的“鲁棒性”
10.6 人工神经网络ANN
ANN模型
BP模型
深度学习
集成学习:Bagging、Boosting、Adaboost
Random Forest算法
【核心名词】:成本函数、激活函数
【优缺点】:
优点:准确率高、健壮性好、输出多样、学习目标函数的快速评估
缺点:训练时间长、可解释性差、参数多且靠经验
【连接方式】:前馈神经网络、反馈神经网络(BP)、层内有互联的神经网络

【BP模型】:
训练过程:正向传播+误差反向传播
训练方法:梯度下降算法

优点:可以逼近非线性映射关系、泛化能力强
缺点:收敛速度慢、局部极值、hidden_layer和node个数难确定
【例题】:
