大模型入门(5)——阶段性小结
到目前为止,我对于LLM的理解用自己的语言总结来说,大致如下:
一个语言模型(LM)的任务是根据上文内容预测下文内容,而大语言模型(LLM)则是利用率大量数据进行训练的语言模型,这称为预训练。
预训练后的LLM能够完成文本生成任务,但是对于人类给出的指令,LLM并不能很好地给出回答,此时引入了监督微调(SFT)方法。SFT通过人类创建的一些固定的、准确的(Prompt,Answer)对,并交给LLM进行学习。
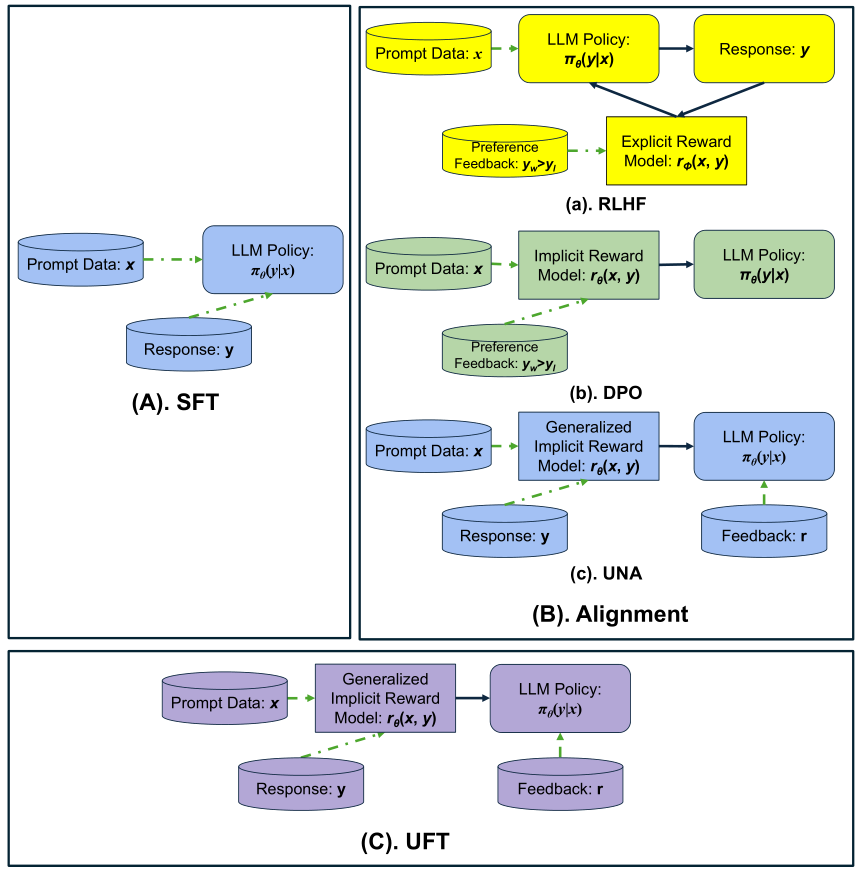
但是在SFT之后,LLM也面临着伦理问题:无意中教唆人类从事不道德的活动。因此,为了对齐人类的偏好,提出了(带PPO的人类反馈强化学习)RLHF、(直接偏好优化)DPO、KTO和(统一对齐)UNA、RAG等方法。
其中RLHF方法先通过训练奖励模型,再使用RL的算法(PPO、GRPO、GPG等)进行强化学习,以提升LLM的推理能力
【SFT与对齐】
LLM的训练分为两部分,预训练阶段和后训练阶段:
在预训练阶段,LLM通过处理海量的文本数据来学习语言的基本结构、语法、语义、事实知识以及世界模型
LLM在预训练之后,需要进行后训练以提升模型特定能力(如推理能力)和对齐人类偏好
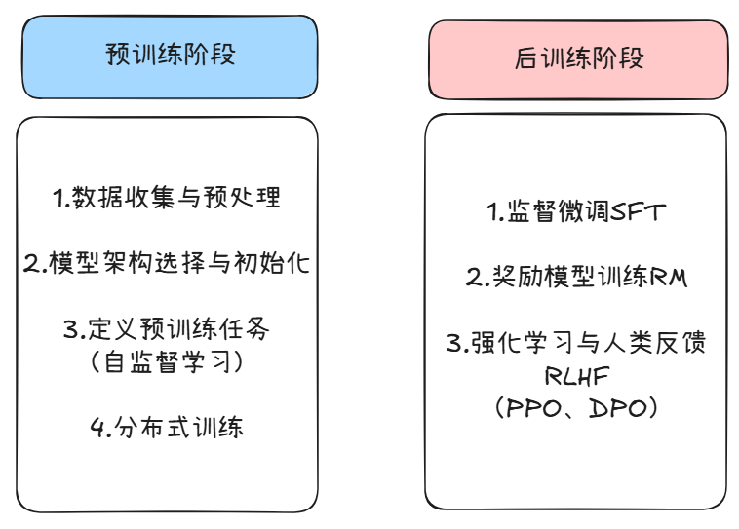
在后训练阶段,常用的增强模型推理能力的技术包括:强化学习(RL)和知识蒸馏(KD)。知识蒸馏旨在训练学生策略 πθ 模仿更强大的教师 πT 的行为,一种简单而有效的方法是最大化教师生成数据上的对数似然,也称为监督微调 (SFT)
目前,使用监督微调(SFT)或拒绝采样微调(RFT)从更强大的教师模型中蒸馏知识已广泛应用于LLM后训练。
KD 在从教师监督中学习方面是有效和高效的,但它受限于教师的能力,并且在域外泛化方面往往表现不佳
相比之下,RL 可以通过自我探索和奖励指导来放大模型本身的有用推理模式,通常会带来更好的泛化。然而,它受到基础模型固有能力的限制,并且需要大量额外的计算来搜索和优化
因此现有策略通常首先应用 KD 来提高模型能力,然后通过 RL 在两个甚至更多独立阶段进一步完善模型。
【基于RL的增强推理能力的方法】:
直接将 RL 应用于预训练模型,如 R1-Zero 类训练
增强蒸馏模型以解锁较小 LLM 的推理边界
开发与特定骨干无关的模型无关的策略改进(比如结合GRPO和KD)
【知识蒸馏】:
LLM 的知识蒸馏 (KD) 可以根据学生是从教师引导的输出(离线策略)还是从自己的样本(在线策略)中学习而大致分为两种范式:
标准 KD 通常依赖于教师采样的分布,并且可以应用于序列级别或令牌-logit 级别
在线策略 KD 基于学生生成的样本和相应的教师 logits 进行优化,这有助于减轻暴露偏差并支持强化风格的训练