代码阅读与运行1
RLHF
试着运行了一份非常基础的RLHF代码,来源于:https://github.com/lansinuote/Simple_RLHF_tiny
B站上有对应视频
📁项目结构
Simple_RLHF_tiny-main/
├── 🔧 核心代码文件
│ ├── util.py # 工具类:TokenizerUtil文本编码解码
│ ├── 0.下载文件.ipynb # 模型下载脚本
│ ├── 1.actor.ipynb # Actor模型训练
│ ├── 2.critic.ipynb # Critic模型训练
│ ├── 3.rlhf.ipynb # 完整RLHF训练流程
│ └── 4.test.ipynb # 模型测试
│
├── 📊 数据与模型
│ ├── dataset/
│ │ ├── train.json # 训练数据 (27MB)
│ │ └── eval.json # 评估数据 (1.8MB)
│ ├── tokenizer/facebook/opt-350m/ # 分词器
│ └── model/facebook/
│ ├── opt-350m/ # Actor模型 (350M参数)
│ └── opt-125m/ # Critic模型 (125M参数)
🔧 核心架构
1.TokenizerUtil 工具类 (util.py)
class TokenizerUtil:
- encode() # 文本编码:添加BOS/EOS,padding
- decode() # 文本解码:去除特殊token
- pad_to_left() # 左填充:用于生成任务
2.三阶段训练流程
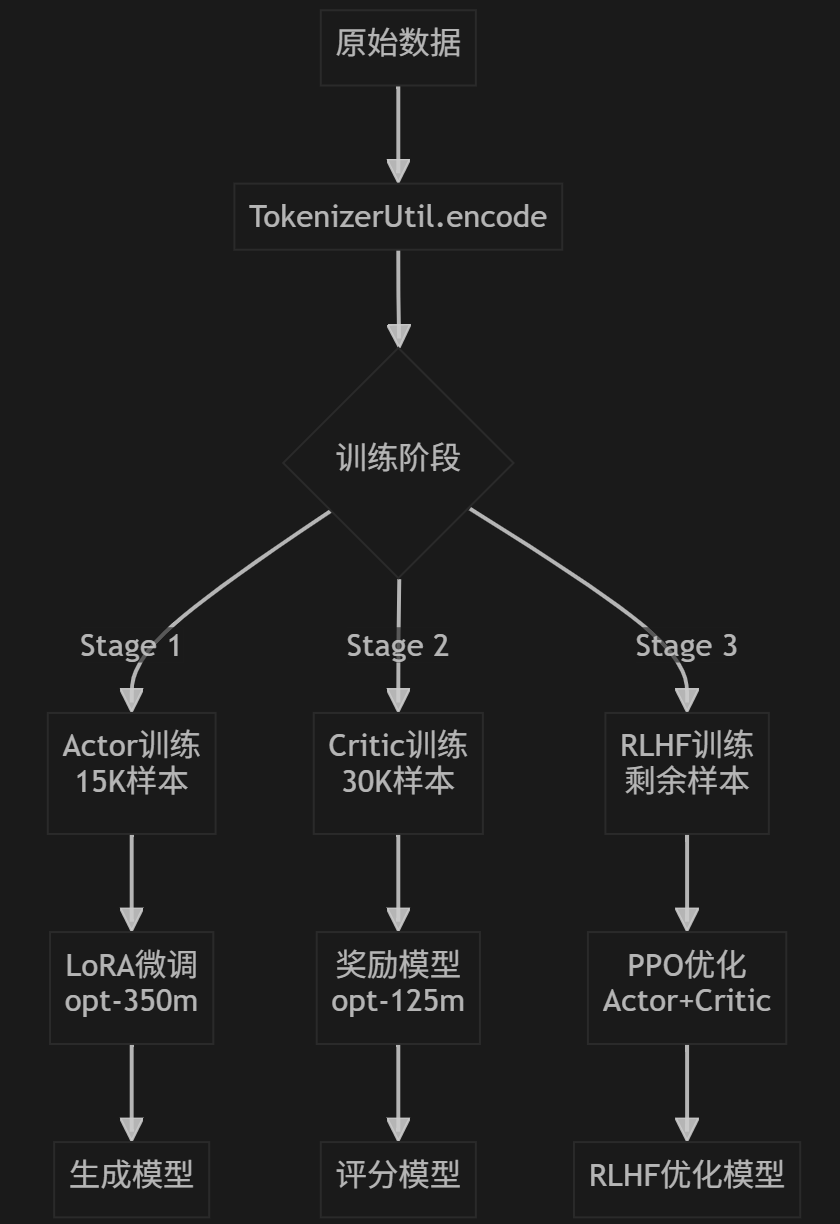
阶段1: Actor训练 (1.actor.ipynb)
├── 数据:train.json[0:15000]
├── 模型:opt-350m → LoRA微调
└── 任务:语言模型训练
阶段2: Critic训练 (2.critic.ipynb)
├── 数据:train.json[15000:45000]
├── 模型:opt-125m → 奖励模型
└── 任务:偏好学习
阶段3: RLHF训练 (3.rlhf.ipynb)
├── 数据:train.json[45000:]
├── 模型:Actor + Critic
└── 任务:强化学习优化
🌐 运行环境
软件环境
操作系统: Windows 10 (Build 26100)
Python: 3.12 (via Anaconda)
虚拟环境: rlhf_env
核心依赖:
- torch: 2.7.1 (CUDA 11.8)
- transformers: 4.38.2
- datasets: 2.18.0
- accelerate: 0.28.0
- peft: 0.9.0 (LoRA微调)
- jupyter: 2.14.1
硬件需求
GPU: 推荐CUDA兼容显卡
内存: >8GB RAM
存储: >2GB (模型+数据)
🏗️ 数据流架构
运行时的一些问题
1.一开始的时候内核选错了,没有显示我创建的虚拟环境,后来发现得安装ipykernel并注册环境
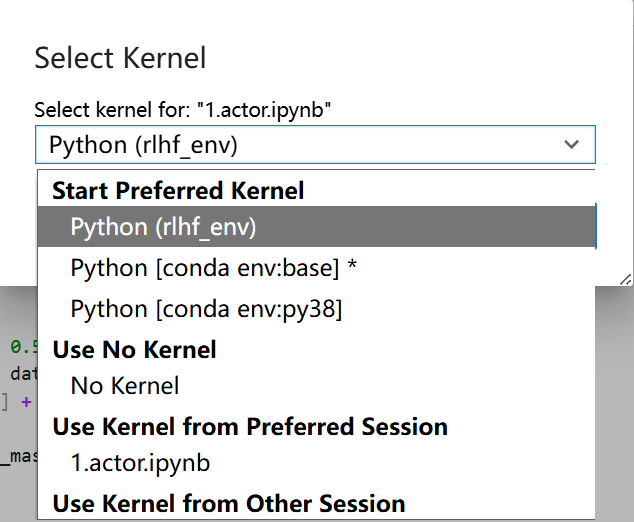
换成rlhf_env的虚拟环境就好了
2.这个估计得跑2h,试图在colab上运行试试
colab的免费GPU是15G的显存,还是比我电脑上区区8G显存的GPU更好
3.actor模型训练时出现的问题有:
FP16混合精度训练出现梯度缩放错误,accelerator.clip_grad_norm_()导致了这个问题
结果
在ai的全权负责下,我成功在colab上运行了自己的代码
https://drive.google.com/drive/folders/1Zek9YAEtAhCNmIEuF9nXVHuk4gD3KMZr?usp=sharing
s