论文阅读(4)——知识蒸馏/GRPO/DPO
A Survey on Symbolic Knowledge Distillation of Large Language Models
这是一篇综述,主要介绍LLM中的符号知识蒸馏。
【知识蒸馏概述】
知识蒸馏是一种将知识从更大、更复杂的模型(教师)转移到更小、更简单的模型(学生)的技术,目标是保留教师模型的大部分性能 。这个过程在计算资源有限或部署需要轻量级模型的情况下至关重要。传统知识蒸馏技术有多种类型:基于响应的、基于特征的和基于关系的,以及一种现代符号知识蒸馏,每种都有其独特的方法和应用领域:
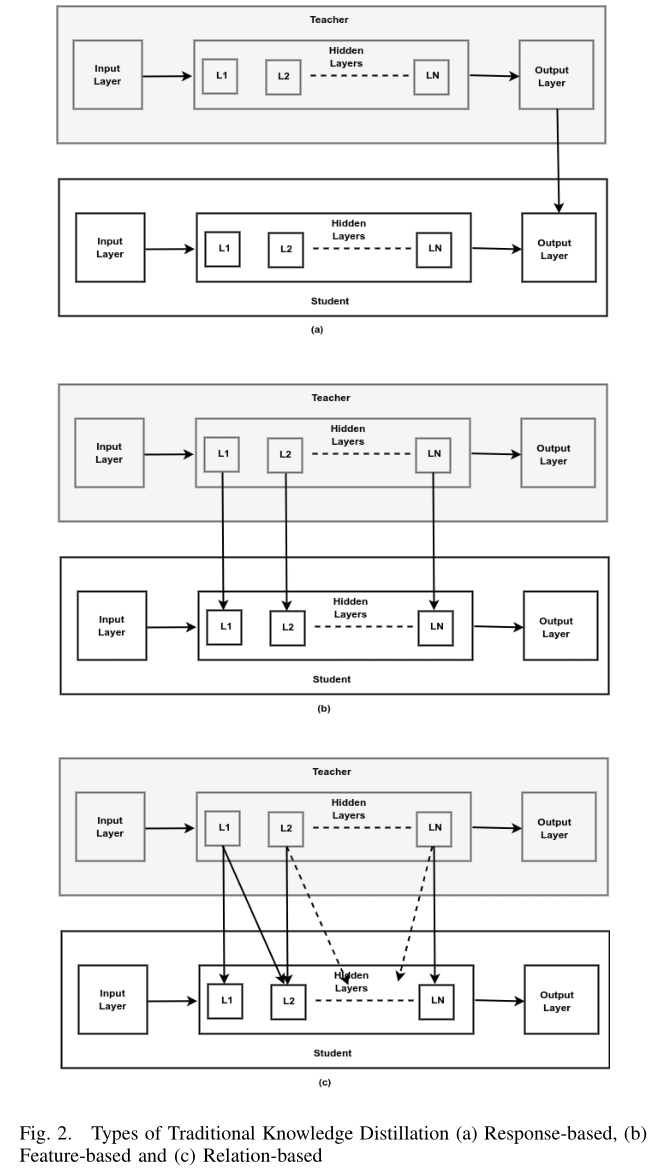
1.基于响应的知识蒸馏:
基于响应的知识蒸馏涉及将知识从教师模型的最终输出层转移到学生模型,旨在模仿教师的最终预测(采用基于教师和学生 logits 之间差异的损失函数)
广泛应用于模型压缩,并已适用于不同类型的模型预测,包括对象检测和人体姿态估计
关键应用是图像分类
缺点是无法充分利用教师的中间级监督
2.基于特征的知识蒸馏:
基于特征的知识蒸馏利用深度神经网络学习分层特征表示的优势,这是表示学习的核心过程。与专注于最后一层输出的基于响应的知识蒸馏不同,基于特征的蒸馏利用中间层或特征图的输出来指导学生模型。
这种方法对于训练更窄更深的模型特别有益,因为它提供了更丰富的训练信号集
由于教师和学生模型之间的尺寸差异,选择合适的提示和指导层仍然存在挑战
3.基于关系的知识蒸馏:
基于关系的知识蒸馏超越了基于响应和基于特征的方法的范围,通过检查教师模型中不同层或数据样本之间的关系。这种方法深入研究了特征图、层之间,甚至不同教师或数据样本之间的动态关系,提供了更细致的知识转移形式
蒸馏损失是根据教师和学生模型特征表示之间的相似性和相关函数制定的,旨在捕获和转移教师架构中存在的复杂关系
还可以包含数据的结构化知识、关于输入特征的特权信息以及各种其他类别,每个类别都由不同的损失函数表示,如 Earth Mover 距离、Huber 损失、角度损失和 Frobenius 范数
4.符号知识蒸馏:
符号知识蒸馏以符号格式的知识蒸馏和传输为中心,包括规则、逻辑或符号表示。这种方法将结构化知识库和规则与机器学习模型相结合,以提高其性能和清晰度。它以允许在推理、推断和决策过程中进行操作的方式编码复杂的结构化信息。这种方法的重要性在于它与人类解释和推理知识的方法相一致,从而提供增强的透明度和可解释性。
知识从复杂的、通常不那么透明的模型(如深度神经网络)中提取并转换为符号的、更易于理解的格式。这种方法融合了传统知识蒸馏和符号人工智能的原理,旨在提高机器学习模型的可解释性、透明度,并可能提高其效率。它充当了深度学习模型通常的“黑箱”性质与对人类可理解和可信赖的模型的需求之间的桥梁
在需要高水平责任和可解释性的领域尤其关键,包括医疗保健、金融和自动驾驶

【符号知识蒸馏的步骤】:
1.训练教师模型:在数据集上训练一个复杂的模型(教师)以实现高性能。该模型可以是深度神经网络,其架构和训练过程取决于具体任务(例如,图像识别、NLP)
2.提取知识:随后的阶段涉及从教师模型中获取见解,这可以通过多种方法实现,包括:检查网络内的神经元激活模式;采用诸如分层相关性传播 (LRP) 或 SHapley Additive exPlanations (SHAP) 等方法来评估各种输入在网络决策过程中的重要性;以及根据网络建立的决策边界识别规则或模式
3.符号表示:收集到的知识随后转换为符号表示。此过程包括:
开发决策树或编译一组模仿神经网络行为的逻辑规则
利用图形模型或其他结构化形式来封装网络所破译的关系和依赖性
4.训练学生模型:在将提取的知识转换为符号形式之后,训练一个更简单、更具可解释性的“学生”模型来模仿这种符号表示。训练过程涉及两种关键策略。符号表示可以直接用作决策的综合规则集,允许学生模型根据预定义的逻辑规则复制决策过程,或者训练学生模型来近似符号表示本身。这种方法通常包含传统的监督学习技术,其显著区别在于从教师模型中提取的符号知识作为指导或目标。
5.评估和改进:一旦学生模型被训练以模仿符号表示,它就会进行评估,以验证它保留了教师模型的关键知识和性能属性这种评估可能会揭示需要调整符号表示本身或学生模型的训练方法。这种改进对于确保学生不仅近似教师的性能,而且以可解释和透明的方式进行近似至关重要
【大语言模型概述】:
1.架构: Transformer 架构是所有 LLM 的骨干。由于其可并行计算、基于注意力的机制等特点,它能够减少对手工特征的依赖,并提高了 NLP 任务的性能。所有 LLM 都直接或间接植根于 Transformer 架构。现有的所有 LLM 都属于以下架构之一:
编码器-解码器架构:这种架构的基本原理是将输入序列转换为固定长度的向量形式,然后将这种表示转换为输出序列。该架构由两组 Transformer 块组成:一个作为编码器,另一个作为解码器。编码器负责处理输入序列,利用一系列多头自注意力层将其转换为潜在表示。然后,解码器通过自回归过程利用这些表示,通过交叉注意力机制关注编码器提供的潜在表示,从而生成输出序列
因果解码器架构:因果解码器架构是一种仅解码器架构,用于语言建模,其中输入和输出令牌通过解码器以相同的方式处理。这种架构包含一个单向注意力掩码,它确保每个输入令牌只能关注过去的令牌本身,通过将所有未来的注意力掩码为零。GPT 系列模型,包括 GPT-1 、GPT-2 和 GPT-3 ,是这种架构的代表性语言模型
前缀解码器架构:前缀解码器架构,也称为非因果解码器,是另一种仅解码器架构,它修改了因果解码器的掩码机制,以实现对前缀令牌的双向注意力,同时仅对生成的令牌保持单向注意力。这使得前缀解码器能够双向编码前缀序列并自回归地预测输出令牌,其中在编码和解码期间共享相同的参数。与因果解码器架构不同,前缀解码器架构可以将双向信息整合到解码过程中,使其更适合需要理解整个输入序列上下文的任务
2.训练过程:LLM的训练过程可分为两个阶段:
预训练:预训练 LLM 涉及在大量未标记的文本数据集上进行训练,以学习通用语言模式和见解。预训练的成功取决于训练语料库的规模和质量,大型、多样化的数据集允许模型捕获各种语言模式并有效地泛化到新数据。
数据收集——通用数据源和专用数据源
数据预处理——去噪、冗余和不相关内容——质量过滤、去重(句子、文档和数据级别)、隐私保护和分词(将文本分割成模型可管理的单元)
微调或自适应微调:微调阶段对于将预训练的 LLM 适应特定领域或任务至关重要,利用标记示例或强化学习来完善模型的理解和预测能力。它包含两种主要策略:指令微调和对齐微调。
指令微调是指通过在训练期间整合显式指令或演示来微调语言模型。这种方法旨在引导模型实现期望的行为和结果,从而促进对任务的更有针对性的响应。此微调的指令可以从现有数据集中获取,并重新格式化以包含清晰的指令,或根据特定的人类需求进行设计
对齐微调旨在调整 LLM 的输出以准确匹配人类期望,这个过程可能涉及一种称为对齐税的权衡。这个概念指的是模型在微调以优先考虑从人类角度被认为更可接受或更有益的输出时,其能力可能受到的潜在损害
【LLM的符号知识蒸馏】
LLM 的符号知识蒸馏旨在将 LLM 中封装的大量知识提炼成更具可解释性和效率的形式。
精心制作自定义提示,引导 LLM 生成富含特定知识类型的输出
采用命名实体识别 (NER)、词性标注 (POS) 和依存句法分析等 NLP 技术来分析和结构化响应,提取有意义的信息并识别文本中的模式,然后将其转换为结构化知识格式,例如逻辑规则、知识图或语义框架
对生成的符号表示进行细化和验证,以保留知识深度并确保其准确性、一致性和实用性。包括使用人类专家或使用训练模型根据质量对生成的知识进行分类来细化符号知识
用于蒸馏 LLM 符号知识的各种方法可分类为:
1.直接蒸馏
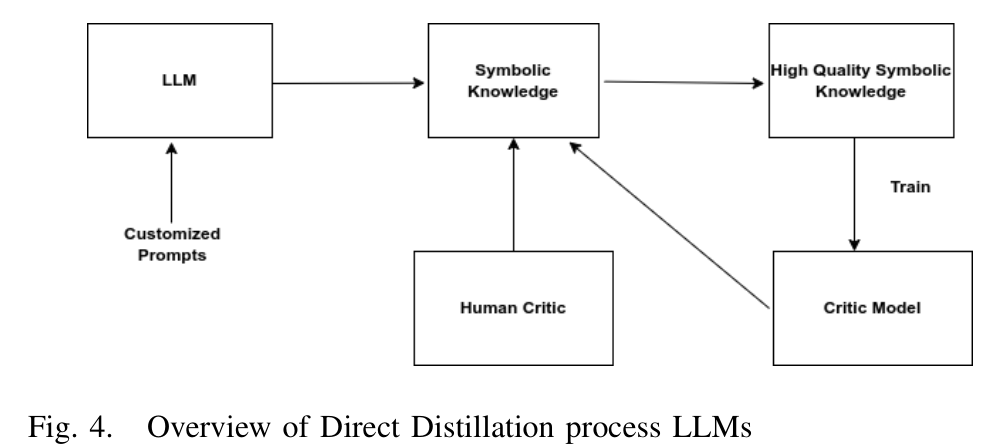
首先构建一个特定提示,引出包含常识或事实理解的响应。LLM 会根据其训练和所提供上下文的复杂性生成响应,此步骤将模型中的隐性知识转换为显式文本响应,可以进一步分析和用于知识提取。然后分析生成的文本以提取知识(通过此过程获得的知识库可以在评论员的帮助下进一步改进),一旦积累了大量高质量的生成数据,这些数据就可以用于训练一个评论模型,过滤掉质量较低的输出,确保只保留高质量的常识知识。然后可以将高质量知识蒸馏成结构化格式,例如知识图,或进一步训练成专门模型
(模型的响应是其学习模式、语言理解以及嵌入在其训练语料库中的隐性知识的复杂相互作用)
2.符号知识的多级蒸馏

这种方法迭代地细化知识从较大的预训练教师模型到较小、更高效的学生模型的转移。该过程始于教师模型,通常是像 GPT-3 这样的 LLM,生成初始知识库。然后对生成的知识库进行质量过。较小的学生模型,例如 GPT2-Large,最初在此过滤后的数据集上进行训练。随后,学生模型生成新的知识库,再次进行过滤以提高质量。这种通过过滤进行生成和细化的循环迭代重复,每次迭代都旨在提高蒸馏知识的保真度和简洁性。
3.使用强化学习策略的蒸馏
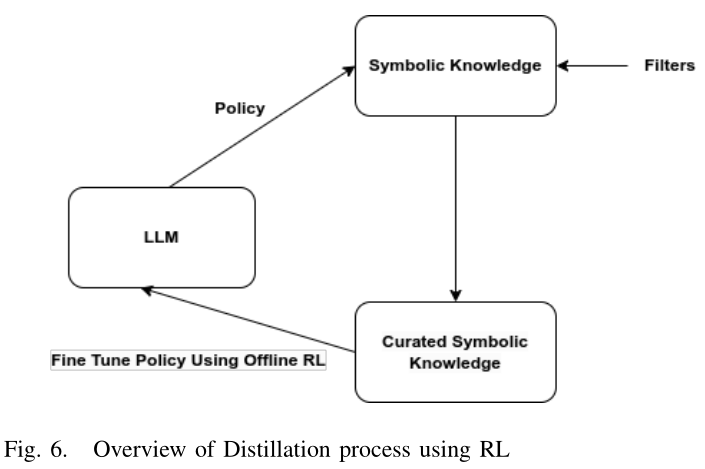
该方法通过两步迭代过程:生成和过滤数据,来优化 LLM 的策略。
第一步涉及使用当前的 LLM 策略为给定上下文生成一系列输出预测,从而有效地扩充训练数据集
第二步使用过滤器(通常是根据人类偏好训练的学习奖励模型)对生成的数据进行排名和过滤
语言模型将使用离线 RL 目标在此精选数据集上进行微调,调整其策略以生成更可能获得高分数的输出。这种生成和过滤的过程,迭代重复,作为反馈循环,不断优化模型的策略,使其输出越来越符合人类偏好。
【应用领域】:
创建更大、多样化和高质量的数据集
通过在人类指导下利用机器进行低级任务来降低成本
比 LLM 更小、更强大的模型,用于摘要、翻译、常识等
指令微调
新颖的算法和评估基准
开源数据和开放模型的创建
LLM 的自我改进(RLHF)
跨领域共生
工业应用
KDRL: Post-Training Reasoning LLMs via Unified Knowledge Distillation and Reinforcement Learning
KDRL:通过统一知识蒸馏和强化学习对推理大型语言模型进行后训练
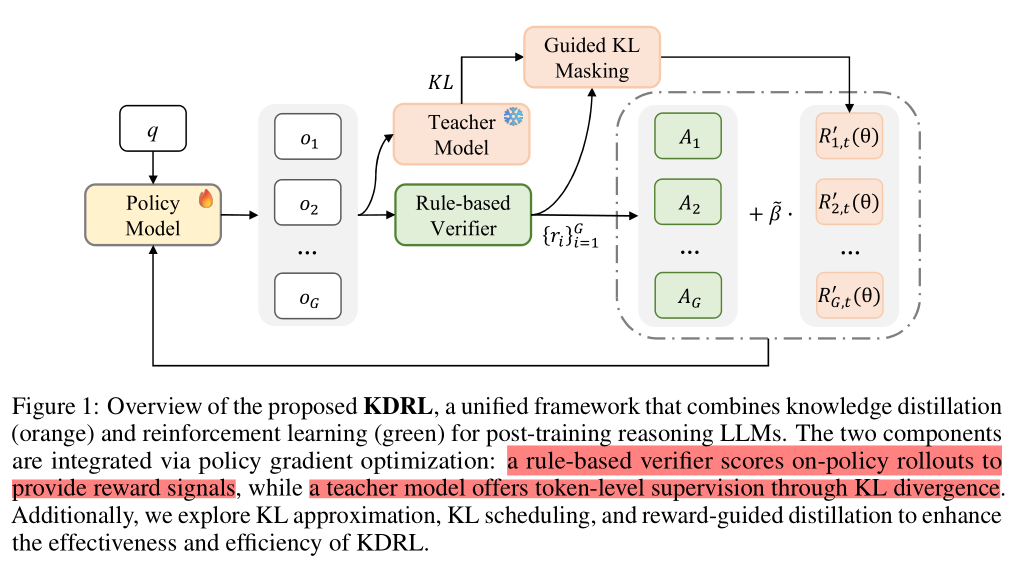
KDRL由两个组件通过策略梯度优化集成:
一个基于规则的验证器对在线策略的输出进行评分以提供奖励信号
一个教室模型通过KL散度提供令牌级监督
【知识蒸馏】:

知识蒸馏旨在训练学生策略 πθ 模仿更强大的教师 πT 的行为 。一种简单而有效的方法是最大化教师生成数据上的对数似然,也称为监督微调 (SFT)。它等价于最小化 πT 和 πθ 之间的前向 KL 散度。
这篇文章《KDRL: Post-Training Reasoning LLMs via Unified Knowledge Distillation and Reinforcement Learning》提出了一种新的大型语言模型(LLM)后训练框架 KDRL,旨在提升 LLM 的推理能力。
文章主要内容总结:
问题背景:
现有的 LLM 推理能力提升方法主要有两大范式:强化学习(RL)和知识蒸馏(KD)。
RL 能够激发复杂的推理行为,但样本效率低,尤其是在初始策略探索高奖励轨迹困难时。
KD 通过模仿教师模型提高学习效率,但泛化能力较差,尤其是在域外场景。
现有方法通常分阶段应用 KD 和 RL,但这种解耦方式可能阻碍后训练的扩展和效率。
KDRL 框架的提出:
KDRL 旨在统一 KD 和 RL,共同优化推理模型,以结合教师监督和自我探索的优势,提高后训练的效率和有效性。
核心思想是利用策略梯度优化,同时最小化学生和教师分布之间的反向 Kullback-Leibler (RKL) 散度,并最大化基于规则的预期奖励。
KDRL 的关键探索点和发现:
GRPO 和 KD-RKL 的组合: 论文探索了奖励塑形和联合损失两种集成方式。结果表明,联合损失(Joint Loss)比奖励塑形更稳定且性能更好。
KL 散度的近似方法: 比较了 k2、k3 和 Top-K 三种 RKL 估计器。
k2 估计器被发现是最佳选择,尽管其本身是有偏估计,但其梯度是无偏的,在下游任务中表现出更好的性能和稳定性。
k3 估计器虽然本身是无偏估计,但其梯度有偏,性能略逊于 k2。
Top-K 近似导致训练不稳定。
RL 和 KD 的平衡(KL 系数): 发现适中的 KL 系数和退火调度(Annealing Schedule)有助于平衡 KD 和 RL。退火调度通过从强模仿平滑过渡到奖励驱动优化,进一步提高了性能。
奖励引导 KD: 提出了奖励引导的 KL 掩码策略(Response-Level Masking),即当响应获得正奖励时,抑制其 KD 损失。这提高了训练和推理的令牌效率,同时保持了可比的性能。
KDRL 的原理是基于策略梯度优化,将**知识蒸馏(KD)和强化学习(RL)**的目标统一到一个框架中。
统一目标函数:
KDRL 的目标函数结合了 GRPO(一种 RL 算法)的目标和反向 KL 散度(RKL)损失。
GRPO 部分: 旨在通过最大化基于规则的奖励来提升模型的推理能力,鼓励模型生成高奖励的轨迹。
RKL 部分: 旨在最小化学生模型与教师模型之间的反向 KL 散度,促使学生模型模仿教师模型的行为。这里使用 k2 近似来计算 RKL 损失,因为它提供了无偏的梯度,有助于优化稳定。
在线策略优化:
KDRL 采用在线策略采样(on-policy sampling),即学生模型基于其当前策略生成响应,然后根据这些响应计算奖励和 RKL 损失。这有助于缓解传统 KD 中存在的“暴露偏差”问题,即训练时使用教师生成的数据,而推理时使用模型自身生成的数据。
平衡与自适应:
通过调整 KL 系数 (β) 来平衡 RL 奖励优化和教师模仿的贡献。
引入 KL 退火调度,使得训练早期更侧重于教师指导(强 β),后期逐渐转向自我探索和奖励驱动(弱 β),从而实现更有效的训练动态。
奖励引导掩码机制允许模型有选择地进行蒸馏,只在模型表现不佳(低奖励)时才应用教师监督,避免对已经正确的输出进行过度正则化,提高了训练效率。
The Key to Fine Tuning Large Language Models for Multi-Turn Medical Conversations is Branching
【RL中的分支架构】
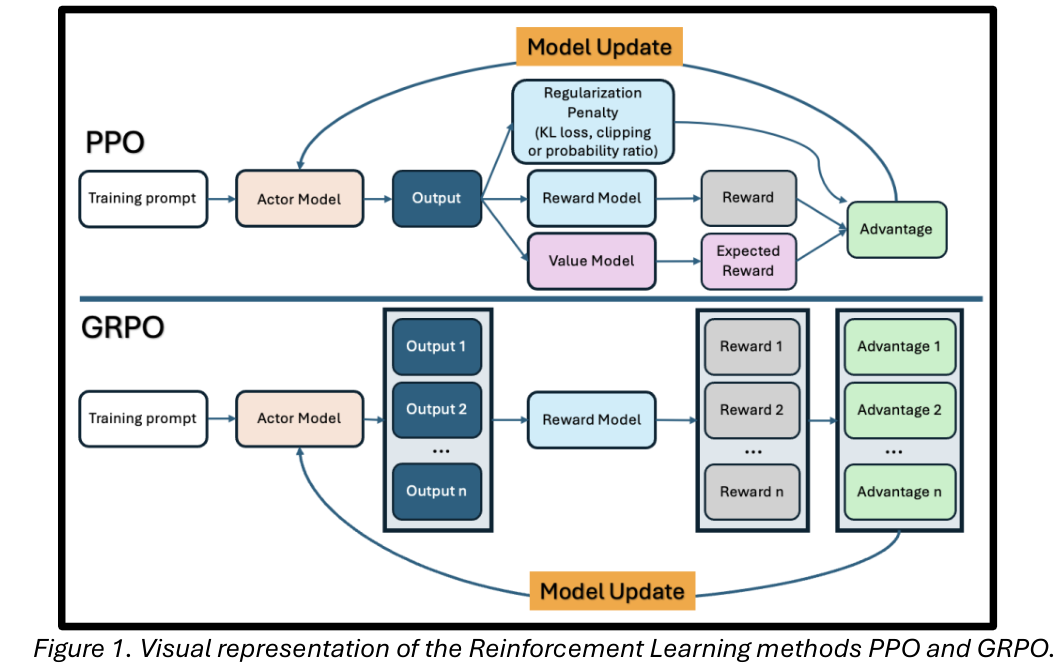
Savage 对话森林 (SCF) 是一种强化学习框架,改编自 PPO 和 GRPO,用于训练大型语言模型 (LLM) 以进行多轮对话。SCF 引入了一种基于树的架构,可以实现对话轮次之间的连接和学习。虽然 SCF 可以应用于各种多轮应用,但这项工作侧重于其在训练医生 LLM 从患者那里获取病史方面的应用。
SCF 的基础架构是 GRPO,但 SCF 不对单轮完成的集合进行分组,而是对一组多轮对话进行采样。如图 2 所示,在两个 LLM 之间模拟对话:医生模型(正在训练的策略)和冻结的患者模型(提示模拟特定的主诉和诊断)。它们共同生成一个由交替轮次组成的对话。在整个对话完成后,它被传递给第三个冻结的诊断模型,该模型生成一个疑似诊断。然后将此诊断与冻结的评分模型提供的金标准诊断进行比较,该模型返回一个标量奖励。
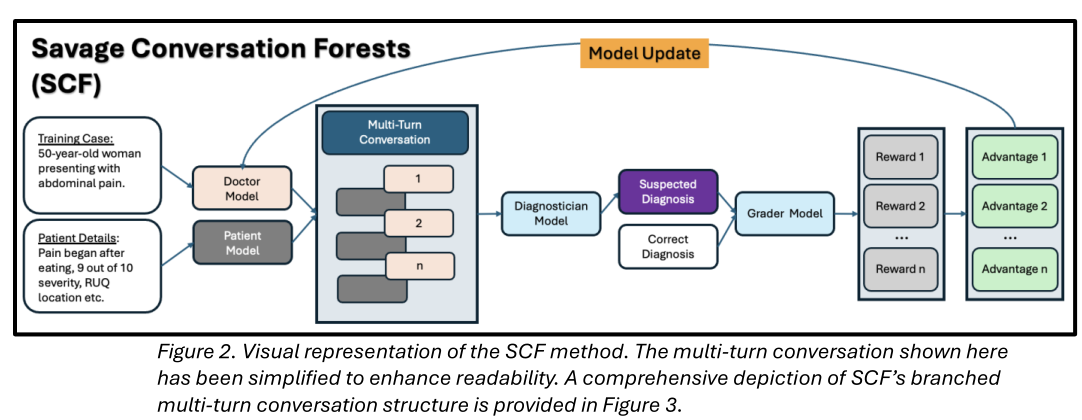
SCF 的关键创新在于对话的结构以及奖励的计算和归一化方式。SCF 不对线性对话轨迹进行采样,而是在每个对话轮次引入分支(如图 3 所示)。每个医生响应都会产生多个可能的延续,从而形成树状结构:所有分支共享一个共同的根(早期对话历史),但在其后续完成中发散。在每个路径或叶子的末端,评分模型提供一个标量奖励。父分支奖励反过来通过对其下游叶子的奖励进行平均来计算。
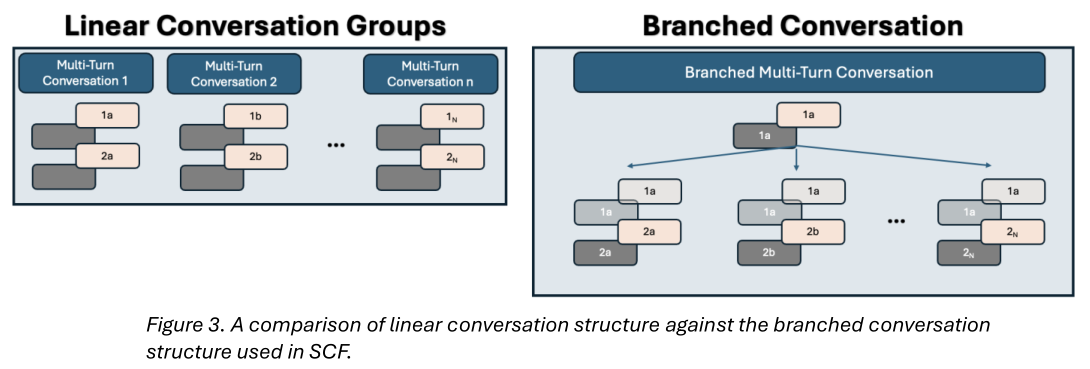
这种分支结构在每个对话级别创建了完成数量的不平衡——这意味着叶子(最终轮次)比父分支(早期轮次)多得多。因此,相对奖励和归一化不能在整个组中统一计算。为了解决这个问题,分支 SCF 使用同级相对奖励计算:每个叶子完成奖励仅与其同级叶子(那些共享相同直接父分支的叶子)进行比较,以计算其相对奖励。然后,SCF 执行深度归一化,其中每个对话深度(例如,父级或叶子)的完成仅与同一级别的其他完成进行归一化。这确保了父分支仅与其他父分支进行比较,叶子仅与其他叶子进行比较。通过将同级相对奖励与深度感知归一化相结合,SCF 保持了上下文公平性和信号稳定性
主要内容:
问题背景: 现有的微调大型语言模型(LLM)的方法,如直接偏好优化(DPO)和群组相对策略优化(GRPO),在单轮任务中表现出色,但在多轮对话应用(特别是医学访谈)中存在局限性。这是因为它们难以捕捉早期对话轮次对后续完成和最终结果的影响。
解决方案提出: 为了解决这一问题,文章引入了“Savage 对话森林”(Savage Conversation Forests, SCF)框架。
SCF 的核心机制: SCF 是一种强化学习框架,它利用分支对话架构来微调 LLM 进行多轮对话。在每个对话轮次,SCF 会生成多个可能的对话延续,形成一个树状结构,使模型能够学习不同早期响应如何影响后续交互和诊断结果。
应用场景: 文章主要关注 SCF 在训练医生 LLM 进行医学病史采集方面的应用。
实验与结果: 通过模拟医患对话,实验比较了带有分支的 SCF、线性 SCF 变体和基础模型的性能。结果表明,带有分支的 SCF 在诊断准确性方面显著优于线性架构和其他基线模型,且能更早、更稳健地识别训练信号。
局限性与未来工作: SCF 的主要局限在于其计算复杂性,随着对话轮次的增加,对话路径呈指数级增长。未来的研究将探索 SCF 在更长对话和更大模型上的应用,并研究其是否能促进更高级的访谈策略。
创新点:
Savage 对话森林 (SCF) 框架: 提出了一种新的强化学习框架,专门用于解决 LLM 在多轮对话中的微调挑战。
分支对话架构: 这是 SCF 的核心创新。与传统的线性对话轨迹不同,SCF 在每个对话轮次引入分支,形成一个树状结构。这使得模型能够探索和学习不同早期决策对整个对话流程和最终结果(如诊断准确性)的影响。
同级相对奖励计算: 为了应对分支结构导致的完成数量不平衡问题,SCF 引入了一种独特的奖励计算方式,即每个叶子完成的奖励仅与其“同级叶子”(共享同一直接父分支的叶子)进行比较。
深度归一化: SCF 还实现了深度归一化,确保在不同对话深度(如父分支或叶子)的完成仅与同一深度的其他完成进行归一化,从而保持上下文公平性和信号稳定性。
首次结合: 据作者所知,SCF 是第一个在多轮 LLM 训练的强化学习框架中,明确结合了树状架构、同级相对奖励计算和深度感知归一化的方法,使其能够捕获现有方法无法捕捉的轮次间相互依赖关系。
Enhancing Large Language Models through Structured Reasoning
通过结构化推理增强大型语言模型
这篇文章认为,LLM在处理复杂推理任务时的局限性来源于它们依赖从海量非结构化数据集中学习到的隐式统计关联,而缺乏系统地表示和操作结构化知识和逻辑关系的显式机制。

这篇文章的主要贡献在于:
提出一种结构化推理方法,构建了结构化推理数据集,展示了其在通过监督微调(SFT)在LLMs中实现结构化推理方面的有效性
MAX-Flow和最长公共子序列(LCS)算法(分别)集成到组相对策略优化(GRPO)中,在保持推理准确性的同时降低了计算复杂性
利用结构化推理的可解释性优势,我们提出了一种评估推理步骤指标的新方法,同时揭示了神经网络层之间推理兴趣的划分
文章提出,传统的LLMs在处理复杂推理任务时存在局限性,因为它们依赖隐式统计关系而缺乏结构化知识表示。受认知科学启发,该方法旨在通过显式结构化推理来弥补这一不足。
主要贡献和方法:
结构化数据转换: 将非结构化数据转换为结构化格式,通过显式标注推理步骤来训练LLMs进行监督微调(SFT)。
强化学习增强: 引入组相对策略优化(GRPO),并结合两种创新算法:
MAX-Flow: 用于评估推理步骤的重要性,优于传统的困惑度指标。
最长公共子序列(LCS): 在保持推理准确性的同时,显著降低计算复杂性,提高效率。
轻量级微调: 仅使用少量(500个)结构化示例和少量(250步)强化学习步骤进行微调,实现了高效训练。
实验结果与优势:
在DeepSeek-R1-Distill-Qwen-1.5B模型上的实验表明,该方法实现了更简洁的推理,在各种场景下表现出稳定的性能,并提高了与优化技术的兼容性。
结构化推理有助于模型生成更简洁的答案,并使其输出在不同采样温度下更加稳定。
结构化分析有助于识别和移除冗余推理步骤,并且揭示了LLM不同层在推理过程中可能扮演的局部和全局角色划分。
Teaching Models to Reason about Vision-Based Code Generation using GRPO
研究动机:
基于视觉的代码生成(将视觉界面、代码截图、手绘草图转换为功能代码)在软件开发中具有重要实际应用。
现有方法(如监督学习和传统强化学习 PPO)在处理真实世界视觉变化(字体、格式)方面存在局限性,且 PPO 需要计算成本高昂的独立价值函数模型。
本研究旨在通过 GRPO 解决这些问题,以实现高效且功能正确的视觉到代码生成。
方法论:
核心方法:采用 GRPO,这是一种新颖的强化学习方法,通过在每个训练示例中采样多个输出并基于组内相对性能计算优势,从而无需单独的价值函数模型。
模型:使用 Qwen2.5-VL-3B-Instruct 作为骨干视觉-语言模型。
数据:基于 HumanEval 数据集,并进行了广泛的视觉增强(包括字体大小、行号显示、语法高亮主题和字体系列的变化),以模拟真实世界的视觉多样性。
奖励函数:定义了双重奖励函数:
语法奖励:基于 Python AST 验证,确保代码语法正确。
执行奖励:通过执行生成的代码并对照 HumanEval 测试用例进行评估,确保功能正确性。
训练策略:模型被提示生成带有
<think>和<answer>部分的结构化响应,以鼓励分步推理。
对比基线:
零样本 (Zero-shot):直接使用 Qwen2.5-VL-3B-Instruct 模型。
监督微调 (SFT):在成功完成的代码上进行标准监督学习。
SFT+DPO:在 SFT 之后,使用偏好对进行直接偏好优化。
主要结果:
GRPO 表现最佳:在增强型 HumanEval 数据集上,GRPO 实现了 55% 的执行成功率,优于基线模型 (45%)、SFT (50%) 和 SFT+DPO (52%)。
学习效率:GRPO 相比基于偏好的方法(如 DPO)展现出卓越的学习效率和样本效率,因为它通过组内相对排名提供了更稳定和信息量更大的学习信号。
训练进展:GRPO 的执行奖励在训练过程中持续提高,从 0.3 提高到 0.55,验证了其在稀疏奖励环境中的有效性。
SFT 的贡献:SFT 主要通过解决响应格式问题来提高性能。
MCP Safety Training: Learning to Refuse Falsely Benign MCP Exploits using Improved Preference Alignment
这篇文章主要讨论了模型上下文协议(MCP)的安全漏洞,特别是“虚假良性攻击”(FBAs),以及如何通过改进对齐策略来增强大型语言模型(LLM)的拒绝能力。
核心要点:
MCP 的安全威胁: MCP 作为一个开放标准,旨在无缝集成 AI 代理,但研究发现它容易受到 FBA 攻击。这些攻击不再需要用户下载恶意文件,攻击者只需在线发布恶意内容即可欺骗 MCP 代理执行攻击。
TRADE 框架: 文章提出了“全面检索代理欺骗”(TRADE)框架,进一步扩大了 MCP 攻击的威胁模型,降低了网络攻击的门槛。
拒绝对齐的挑战: 尽管许多主流 LLM 经过了广泛的安全对齐,但它们在拒绝 FBA 方面表现不佳,特别是基于 GRPO 的模型。
新型对齐方法:
DPO(直接偏好优化): 离线对齐方法,虽然能提高 LLM 的拒绝能力,但效果有限。
RAG-Pref(用于偏好对齐的检索增强生成): 一种新颖的在线、免训练对齐算法,显著提高了 LLM 的拒绝能力,尤其对 GRPO 模型效果显著。
离线与在线对齐的互补性: 文章强调,DPO 和 RAG-Pref 结合使用时,能最大程度地提高 LLM 的拒绝能力,RAG-Pref 充当了对离线学习的“测试时提醒”。
拒绝指标的重要性: 提出了多代拒绝指标(严格拒绝、多数拒绝、平均拒绝),并强调在评估 MCP 攻击的严重性时,应优先考虑最坏情况下的“严格拒绝率”,因为其他指标可能会大大夸大安全性。
结论:
文章指出,MCP 攻击的门槛很低,现有 LLM 在拒绝 FBA 方面存在不足。通过引入 MCP-FBAs 数据集和 RAG-Pref 算法,并结合 DPO,可以显著提高 LLM 的安全防护能力。同时,呼吁在未来的研究中采用更严格的多代拒绝评估指标,以准确反映真实世界的安全风险。
【MCP】:模型上下文协议是一种用于连接生成式AI组件。
通过标准化大型语言模型(LLM)、支持工具和数据源之间的 API 调用,MCP 充当了一个通用协议,可无缝集成跨广泛使用的服务/应用程序的代理,从而取代了之前设计特定于应用程序的代理 API 的碎片化方法
MCP 已被主要服务广泛采用Google Cloud [21]、Slack [7]、Copilot [35]、Stripe [41]、HuggingFace Tiny Agents [11]——以及行业领先的 LLM——例如,Anthropic 的 Claude [6]、OpenAI 的 gpt-4o/01/03/04 [36] 和 Google 的 Gemma/Gemini [20]
【对LLM的攻击】
AAs(攻击性攻击)——明确包含有害短语或可疑文本的攻击提示
FBAs(虚假良性攻击)——不含害短语但保持随意/中性语气的攻击提示
RADE(检索代理欺骗)
TRADE(全面检索代理欺骗)
【本文中的对齐方法】
DPO
RAG(检索增强生成):它允许 LLM 在生成答案之前,先从外部知识库中检索相关信息
1.构建知识库:将大量的文档、网页、数据库等非结构化或半结构化数据处理成可检索的格式。这通常涉及将文本分割成小块(chunks),并使用嵌入模型将其转换为向量表示(embeddings)。这些向量存储在一个向量数据库中
2.用户查询:当用户提出一个问题时,该问题也会被转换为一个向量
3.信息检索:使用用户的查询向量在向量数据库中进行相似性搜索,找出与查询最相关的文档块。这些检索到的文档块就是 LLM 生成答案的“证据”
4.增强提示:将检索到的相关信息(文档块)与原始的用户查询一起作为输入,构建一个新的、更丰富的提示,然后将其提供给 LLM
5.生成响应:LLM 基于这个增强的提示生成最终的答案。由于 LLM 现在有了外部提供的上下文信息,它能够生成更准确、更相关且不易出现幻觉的响应
RAG-Pref:核心在于它不只是检索“知识”,而是检索“偏好信息”
1.构建偏好知识库——偏好样本库/非偏好样本库
2.用户查询
3.检索偏好和非偏好样本:RAG-Pref 会同时在偏好样本库和非偏好样本库中检索与用户查询最相似的样本。它会检索出一定数量的“偏好”样本和一定数量的“非偏好”样本
4.构建偏好对齐提示:将检索到的偏好样本和非偏好样本作为上下文信息,与原始用户查询一起,构建一个特殊的“偏好对齐提示”。这个提示会明确地向 LLM 指示哪些行为是期望的(基于偏好样本),哪些行为是需要避免的(基于非偏好样本)
5.LLM生成响应:LLM 根据这个包含了偏好信息的增强提示来生成响应。通过这种方式,LLM 在推理时被“提醒”了安全对齐的知识,从而更有可能拒绝 FBA 或采取更安全的行动
RAG-Pref 的优势:
免训练对齐: RAG-Pref 是一种“在线”对齐方法,它不需要对 LLM 进行额外的训练或微调。这意味着可以更灵活、更快速地部署安全防护,而无需承担昂贵的训练成本。
显著提高拒绝率: 实验表明,RAG-Pref 能显著提高 LLM 拒绝 FBA 的能力,甚至对那些通过传统离线对齐(如 DPO)效果不佳的模型也有效。
与离线对齐互补: RAG-Pref 可以与离线对齐方法(如 DPO)结合使用,进一步增强 LLM 的安全防护能力。它不是替代离线对齐,而是作为一种补充机制,在推理时强化模型的安全意识。
实时适应性: 偏好知识库可以相对容易地更新,使模型能够适应新的攻击模式或安全策略。
Exploring the Limits of Model Compression in LLMs:A Knowledge Distillation Study on QA Tasks
这篇文章《探索大型语言模型(LLMs)压缩的极限:基于问答任务的知识蒸馏研究》主要探讨了在资源受限环境中部署大型语言模型时,如何通过知识蒸馏(Knowledge Distillation, KD)技术对其进行压缩,同时保持其在问答(Question Answering, QA)任务上的高性能。
主要发现和贡献包括:
高效的模型压缩: 研究表明,通过知识蒸馏,学生模型(如Qwen2.5-3B和Pythia-1.4B)在参数量大幅减少(最高达57.1%)的情况下,仍能保留其教师模型90%以上的性能。这表明KD是一种有效的LLM压缩策略,使其更适合资源受限的部署。
提示策略的影响: 单样本(one-shot)提示通常能进一步提升压缩模型的性能,尤其是在跨语言问答任务(如MLQA德语子集)中。这强调了少样本学习在压缩模型中的实用性。
蒸馏优于微调: 蒸馏的学生模型普遍优于直接微调的同等大小模型,这表明KD不仅能有效压缩模型,还能增强其从提示中泛化的能力。
模型大小与性能的权衡: 性能下降与模型大小的减小呈正相关,尤其是在参数量极小的模型上。同时,研究也发现存在一个容量阈值,低于该阈值,少样本学习的效果会减弱。
评估中的不一致性: 在某些情况下,验证集和测试集上的性能存在不一致性(例如Pythia模型在SQUAD数据集上的表现),这提示了提示结构和数据集分布差异可能带来的敏感性问题,强调了仔细设计提示和评估设置的重要性。
结论:
文章总结认为,知识蒸馏与少样本提示相结合,为构建紧凑、可泛化且经济高效的语言模型提供了有前景的方向,适用于现实世界部署。研究结果还暗示,这些发现可能泛化到其他可以重新表述为问答问题的NLP任务。
Distilling Empathy from Large Language Models
这篇文章探讨了如何将大型语言模型(LLMs)的同理心能力提取(蒸馏)到小型语言模型(SLMs)中,以便SLMs能在资源受限但人机交互频繁的设备上更好地应用。
文章的核心内容包括:
重要性: 强调了在将LLMs知识提取到SLMs时,保留LLMs的同理心能力至关重要,因为SLMs常用于与人类紧密互动的场景(如智能手机)。
两步微调过程: 提出了一种创新的两步微调方法,首先进行监督微调(SFT),然后通过直接偏好优化(DPO)进行强化学习与人类反馈(RLHF)。这利用了高同理心响应进行SFT,并利用(低,高)同理心响应对进行RLHF,以提升SLMs的同理心表现。
三种同理心提取方法:
直接同理心提取: LLM直接生成同理心响应。
针对人类响应的同理心改进: LLM在给定人类响应的基础上进行同理心改进。
针对LLM初始响应的同理心改进: LLM在自己生成的初始响应基础上进行同理心改进,这种方法在评估中表现最佳,且无需人类参与数据集的准备。
四种提示策略: 设计了四种独特的提示策略,用于有针对性的同理心改进,包括:
仅改进一个特定同理心维度(认知、情感、同情)。
同时改进所有三个维度。
顺序改进三个维度。
识别并改进最缺乏的同理心维度。
评估结果: 评估表明,通过两步微调和有针对性的同理心改进提示增强的数据集,SLMs在生成同理心响应方面的表现显著优于基础SLMs,胜率超过90%,