论文阅读(2)——微调及相关技术
Unearthing Gems from Stones: Policy Optimization with Negative Sample Augmentation for LLM Reasoning
(从石头中挖掘宝石:LLM推理中负样本增强的策略优化)
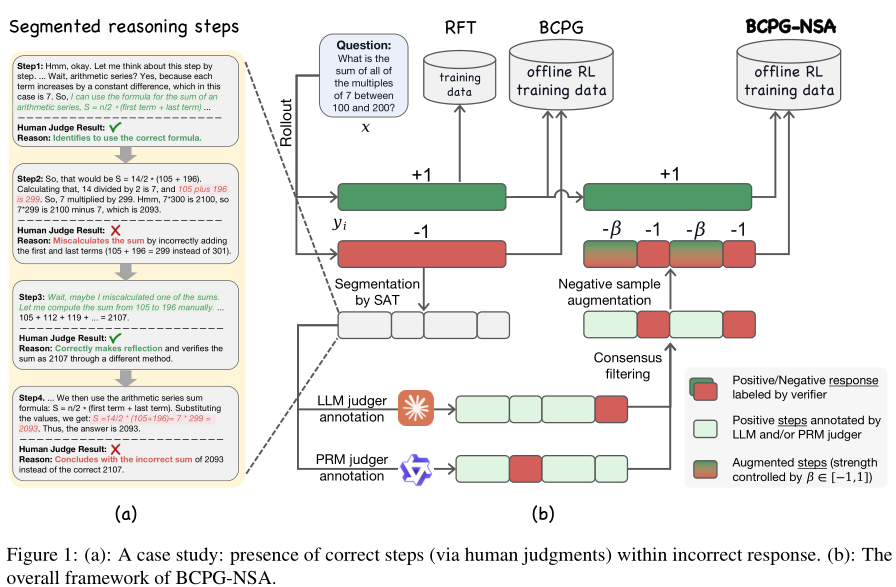
这篇文章提出了BCPG-NSA(行为约束策略梯度与负样本增强)这种新的离线RL框架,主要通过蒸馏出短CoT推理中负样本中有价值的信号,从而实现LLM的长CoT推理。
baseline有:
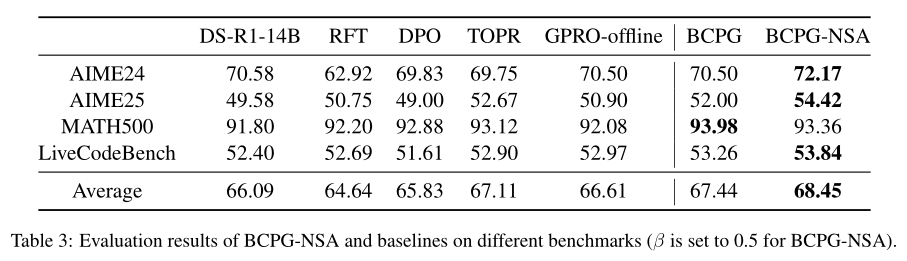
RFT (Yuan et al., 2023): 它只利用离线RL数据集中的正样本,并通过SFT损失更新模型参数。
DPO (Rafailov et al., 2023): 它是一种在离线RL设置中突出的方法,直接优化偏好目标而无需显式奖励建模。该方法在基于偏好的学习任务中表现出卓越的有效性。
TOPR (Roux et al., 2025): 作为一种离线RL变体,它结合了截断重要性采样用于负样本,以及RFT风格的优化用于正样本,并移除了KL正则化。
GRPO-offline (Shao et al., 2024): 它在整个离线RL训练过程中始终应用GRPO损失,消除了周期性在线数据重采样的需求。
(GRPO (Shao et al., 2024) 和GPG (Chu et al., 2025),将负样本中的每个步骤都视为不正确,并使用相同的强度来降低不正确响应中所有token的可能性)
可以看出现有方法要么丢弃负样本要么施加同等惩罚,BCPG-NSA通过三个关键组件实现对负样本的细粒度处理:
语义步骤分割
基于共识的步骤正确性评估
负样本增强的策略优化
【文章框架】:
【算法实现】:

【实验结果】:
UFT: Unifying Fine-Tuning of SFT and RLHF/DPO/UNA through a Generalized Implicit Reward Function
(UFT:通过广义隐式奖励函数统一SFT与RLHF/DPO/UNA)
本研究介绍了一种名为统一微调(UFT)的新方法,旨在解决大型语言模型(LLM)在顺序应用监督微调(SFT)和对齐(如RLHF、DPO、UNA)时出现的性能下降问题。UFT将SFT和对齐集成到一个单一的训练阶段中,使用相同的目标和损失函数,通过一个隐式奖励函数来实现。
UFT通过利用广义隐式奖励函数,遵循UNA的工作,统一了SFT和对齐。仅在指令微调数据上训练,UFT优于SFT,这归因于通过KL散度最小化与预训练模型的差异。通过将指令微调数据与对齐数据混合,UFT超越了所有三种顺序SFT+对齐方法,减轻了性能下降。最终,我们建立了一个与预训练并行运行的统一微调框架。
【对齐税(Alignment Tax)】:是LLM在进行对齐(alignment)操作后,其在某些任务上的性能突出下降的现象。
原因在于:
目标冲突:SFT和对齐阶段的目标可能产生冲突。SFT旨在提高模型在特定指令下的问答能力和文本生成质量,而对齐则侧重于安全性和伦理性。当模型被强制适应新的对齐目标时,它可能“遗忘”或削弱了之前通过SFT学到的一些能力。
数据分布差异:对齐训练所使用的数据(通常是人类偏好数据或奖励信号)可能与SFT所使用的指令微调数据分布不同,这可能导致模型在适应新数据分布时,对旧数据分布上的性能产生负面影响。
之前阅读的时候产生了一个问题,如果说对齐的引入会产生对齐税从而降低模型的性能,那么RL存在的意义在哪?
后来才理解主要有以下的原因:
1.提升模型的实用性和用户体验
指令遵循:RLHF等对齐方法通过人类反馈,让模型学会如何更好地理解用户意图,并生成符合指令的响应。这使得LLM从一个简单的生成器变成一个真正有用的“助手”。文章中提到UFT在
ifeval(指令遵循)任务上的显著改进,这直接体现了对齐对实用性的提升。避免重复和冗余
个性化和偏好适应
2.提高事实性和真实性
对齐过程可以训练模型更倾向于生成真实、准确的信息,并避免“幻觉”(hallucination)。如果人类反馈或奖励模型惩罚不真实的信息,模型就会学习避免这些错误。文章中强调UFT在
truthful任务(事实性)上的显著改进,这表明对齐对于提高模型的事实准确性也至关重要。
3.安全性和伦理道德
Not All Correct Answers Are Equal: Why Your Distillation Source Matters
(并非所有正确答案都相同:为什么您的蒸馏源很重要)
本文探讨了知识蒸馏在增强开源语言模型推理能力方面的有效性,并强调了教师模型选择的重要性。
这篇文章告诉我们,模型测试出现相同结果并不能说明模型的性能一致,而是和训练的数据源质量、结构存在差异,自然对后续训练的贡献可能存在显著差异。
这里的AM模型数据结构上好在哪:
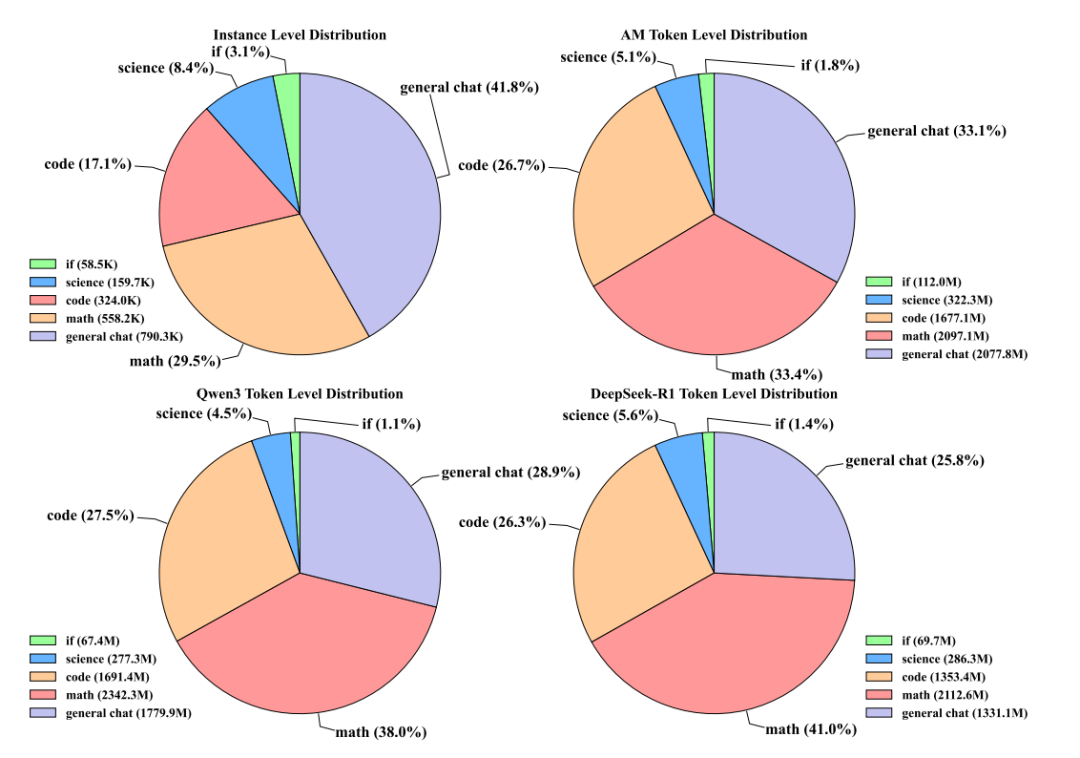
1.AM的token 长度分布更加多样
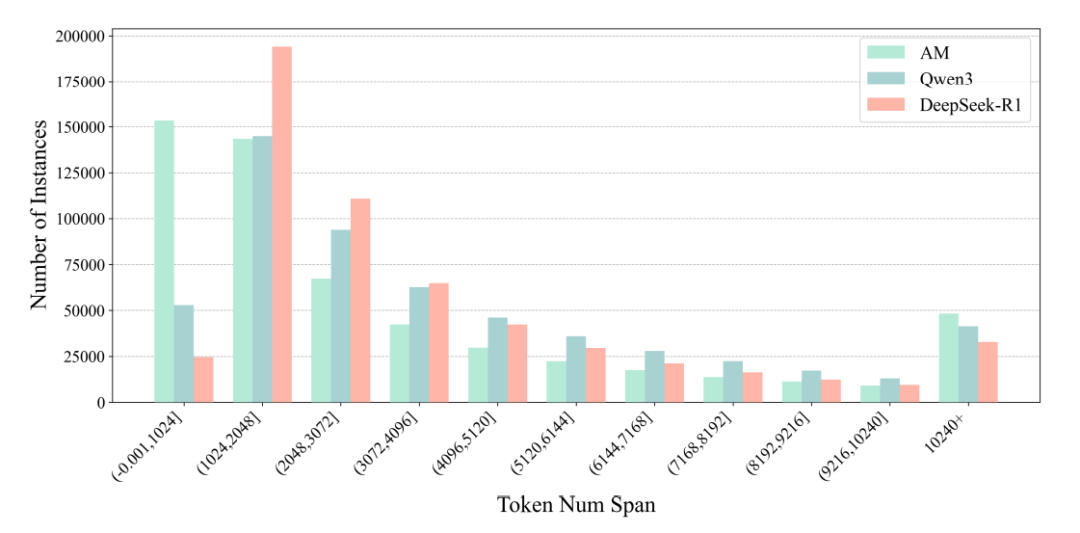
AM-Thinking-v1 的数学数据呈现出高度分散的分布状态,呈现了更多的短序列。
这意味着,AM的响应跨度广——它既能生成简洁的1024 token以内回复,也能输出超过 10240 token 的复杂推理链,这种“长短结合”的分布为模型的自适应能力提供了数据支撑。
2.AM 模型数据源的困惑度更低
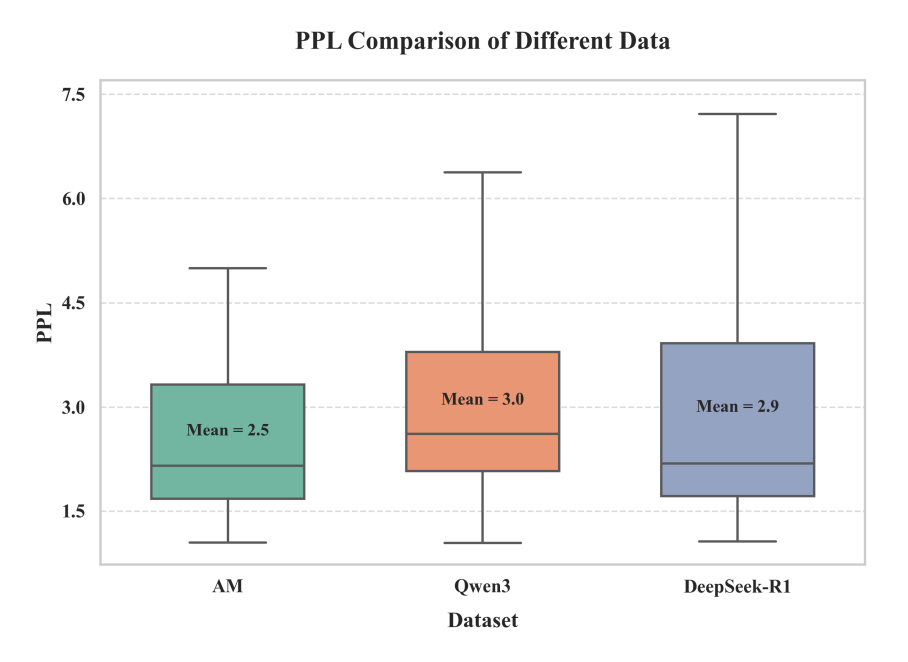
Learning to Reason under Off-Policy Guidance
(在离策略指导下学习推理)
本文介绍了LUFFY(Learning to reason Under oFF-policy guidance),这是一个旨在增强大型推理模型(LRMs)推理能力的框架,特别是在可验证奖励的强化学习(RLVR)背景下。
现有的RLVR方法本质上是“在策略”的,这意味着它们只能从模型自身的输出中学习,从而限制了模型获得超越其初始能力的推理能力。这导致模型在性能上出现瓶颈,无法引入真正新颖的认知能力。
LUFFY通过引入离策略推理轨迹来解决这一限制。它结合了:
混合策略GRPO: 将高质量的离策略推演(来自更强大的模型)与模型自身的在策略推演相结合。当模型难以独立生成正确解决方案时,离策略推演会获得更高的优势,从而引导模型模仿这些高质量的轨迹。当模型开始成功推理时,在策略推演则占据主导地位,鼓励自我探索。
通过正则化重要性采样的策略塑形: 解决了混合策略GRPO可能导致的探索减少和熵崩溃问题。通过重新加权离策略分布的梯度,它增加了对低概率但关键动作的学习强调,从而鼓励模型在整个训练过程中保持探索,避免陷入肤浅的模仿。
(感觉这个只是说利用更好的模型优化自身,比较无聊)
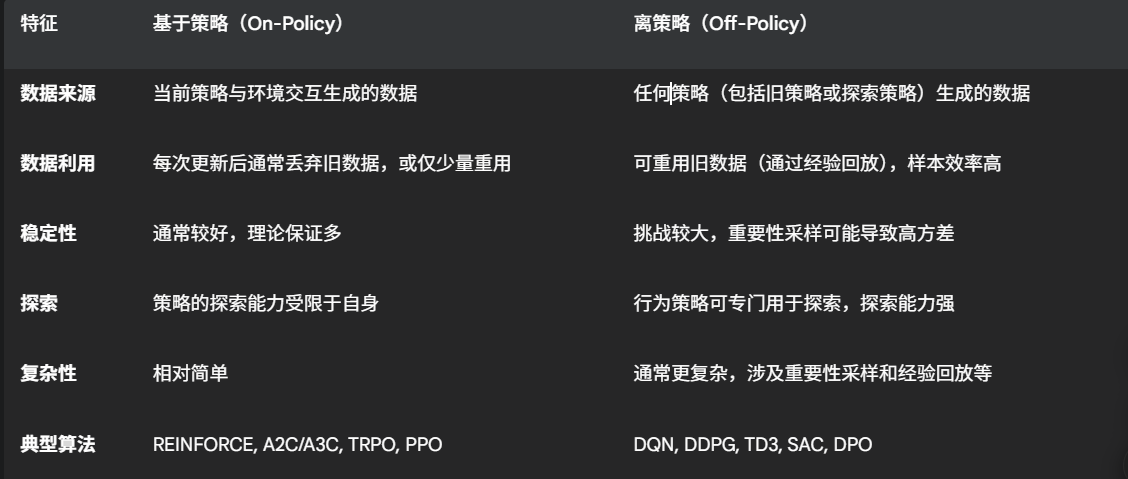
基于策略和离策略方法
1.基于策略方法:
基于策略方法是指智能体(Agent)在学习和更新其决策策略时,只能使用由当前策略与环境交互所生成的数据。换句话说,用于策略改进的经验数据必须来自正在被学习和改进的同一个策略。
REINFORCE: 最早的策略梯度算法之一。
A2C/A3C (Advantage Actor-Critic): 结合了策略梯度和价值函数估计。
TRPO (Trust Region Policy Optimization): 通过限制策略更新幅度来提高稳定性。
PPO (Proximal Policy Optimization): TRPO的简化版本,在实践中表现出色且易于实现。
2.离策略方法:
离策略方法是指智能体在学习和更新其决策策略时,可以使用由不同于当前策略(行为策略)所生成的数据。这意味着智能体可以利用过去经验、其他智能体的经验或一个专门用于探索的策略所收集的数据来改进其目标策略(学习策略)。
DQN (Deep Q-Network): 基于Q学习,利用神经网络和经验回放。
DDPG (Deep Deterministic Policy Gradient): 结合了DQN和策略梯度,用于连续动作空间。
TD3 (Twin Delayed DDPG): DDPG的改进,进一步提高了稳定性。
SAC (Soft Actor-Critic): 引入了最大熵框架,鼓励探索并提高稳定性。
DPO (Direct Preference Optimization): 一种较新的离策略方法,通过偏好学习直接优化策略。
Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
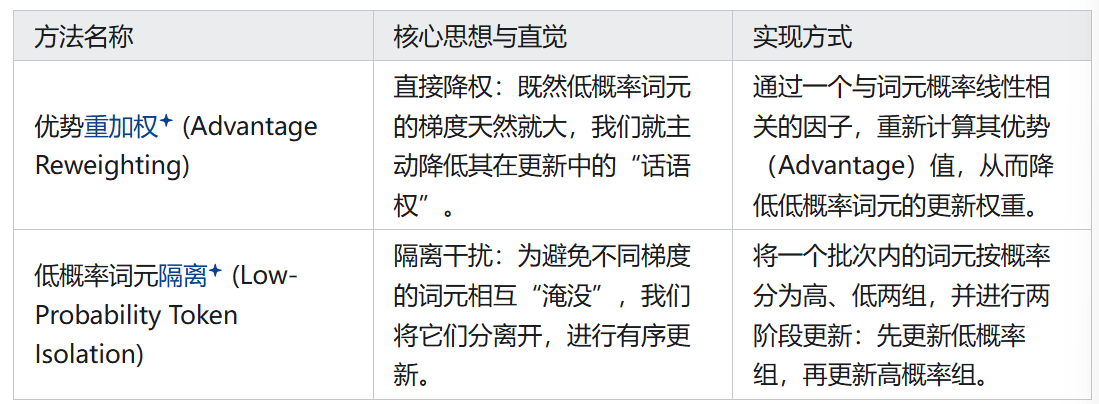
这篇文章探讨了大型语言模型(LLM)在强化学习(RL)训练中面临的一个关键问题:低概率词元由于其较大的梯度幅度,在模型更新中占据了过度的支配地位。这种现象会阻碍高概率词元的有效学习,而这些词元对于LLM的性能至关重要。
为了解决这个问题,研究团队提出了两种新颖的方法:
优势重加权(Advantage Reweighting):通过根据词元的概率重新加权其优势,来降低低概率词元的更新权重。这种方法计算成本极低。
低概率词元隔离(Low-Probability Token Isolation, Lopti):将低概率词元和高概率词元分开,并优先更新低概率词元。这种方法虽然计算成本略高,但效果显著。
当然文章在消融实验中同样也发现高概率词元同样重要,并且Lopti的顺序很重要
ADVANTAGE-GUIDED DISTILLATION FOR PREFER- ENCE ALIGNMENT IN SMALL LANGUAGE MODELS
双约束知识蒸馏(DCKD)
DCKD首先使用DPO直接对教师模型进行微调,得到捕获人类偏好的教师策略。
然后,蒸馏过程最小化教师和学生模型在偏好的非偏好响应的输出分布之间的散度。
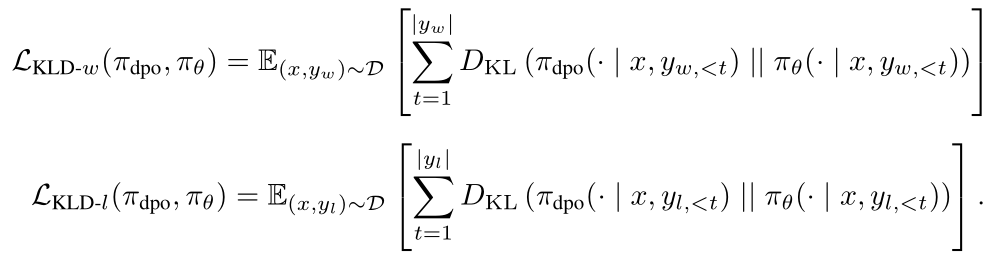
包括偏好响应上的SFT项,DCKD的总体目标是:
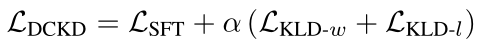
DCKD与传统知识蒸馏的两个关键区别:
DCKD从一个经过DPO微调的偏好对齐教师模型进行蒸馏,这提供了更丰富的偏好信息
它最小化偏好和非偏好响应的KL散度,使学生模型能够更好地理解(区分)人类偏好的细微差别
优势引导蒸馏偏好对齐(ADPA)
DCKD能将偏好知识从教师直接转移到学生,但是它侧重于使学生的输出分布于教师的输出分布对齐。因此,学生模型可能缺少区分积极响应和消极响应的能力。这引出了ADPA。
ADPA核心是利用DPO训练的教师模型和预DPO参考教师模型之间的差异来推导优势函数,该优势函数量化了每个动作的相对偏好,突出了DPO教师与参考教师相比更偏爱(或更不偏爱)某个动作的程度。通过关注这种差异,学生模型能学习到哪些动作更符合人类偏好。
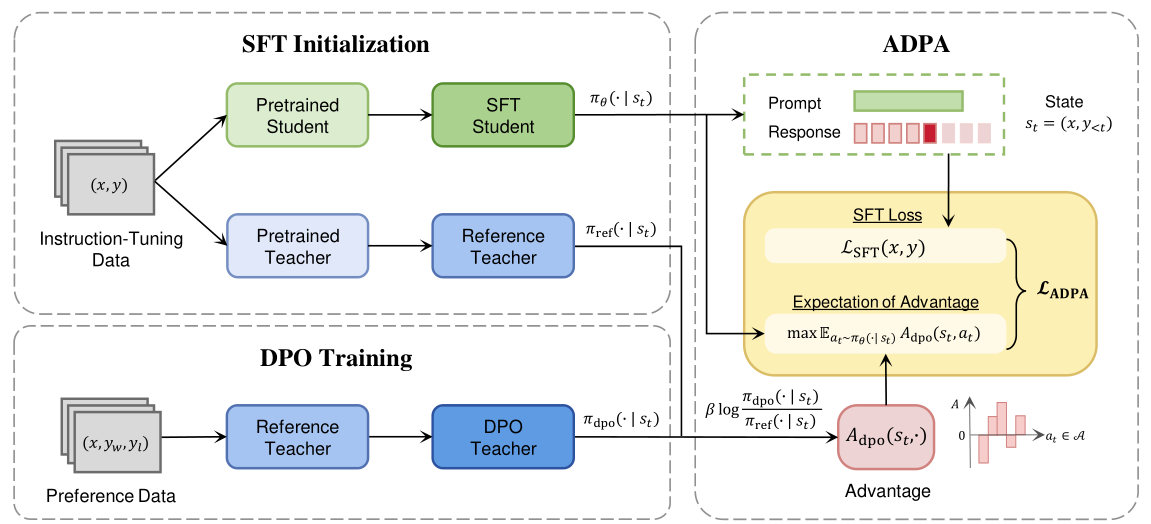
在偏好数据上微调的DPO教师模型和在指令微调数据上微调的参考教师模型
优势函数如下:
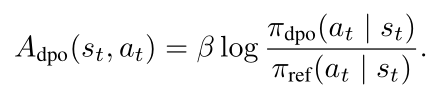
ADPA训练目标是最大化学生测量的预期优势

ADPA损失函数定义为:
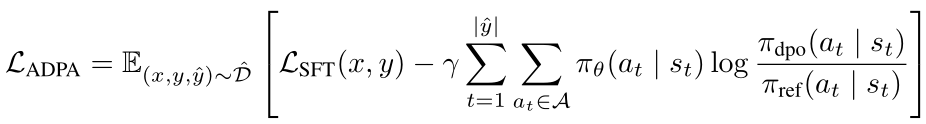
ADPA损失函数的梯度分析(如何指导学生策略)
1.学生模型被引导增加具有正优势(偏好动作)的动作的概率,并降低具有负优势(非偏好动作)的动作的概率
2.通过根据优势的大小加权更新,学生获得细粒度指导,强调相对偏好
ADPA缓解了传统RLHF中典型的稀疏奖励信号问题,还消除了对在线RL的需求。
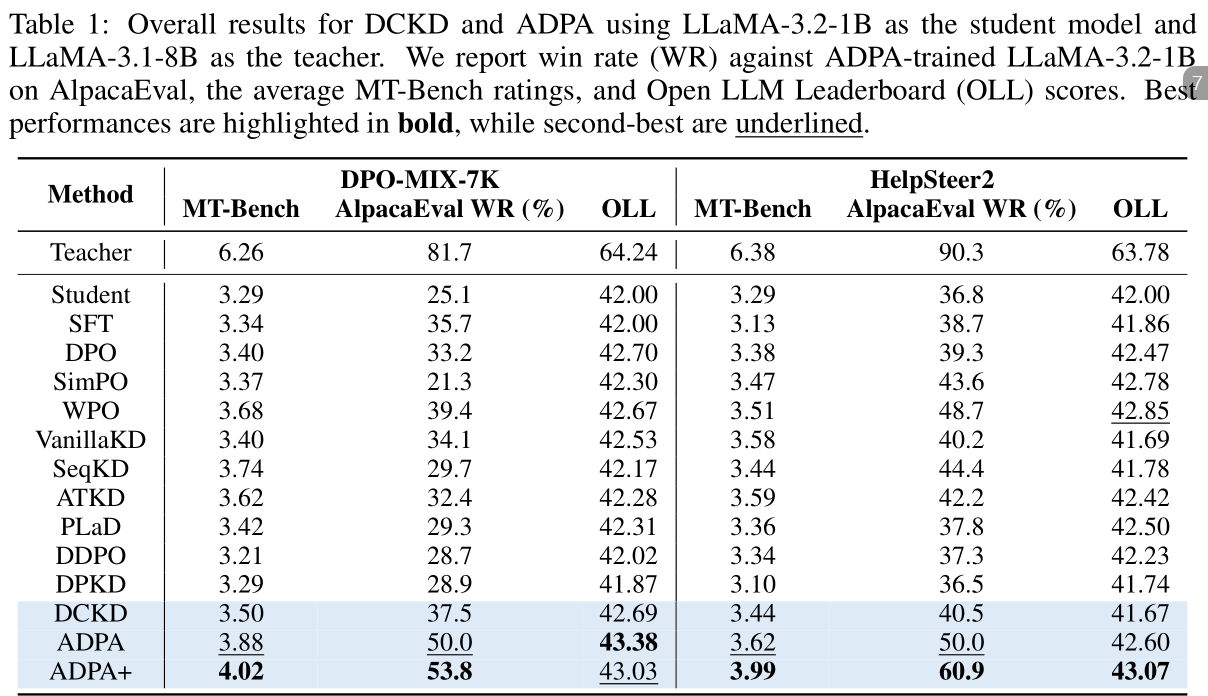
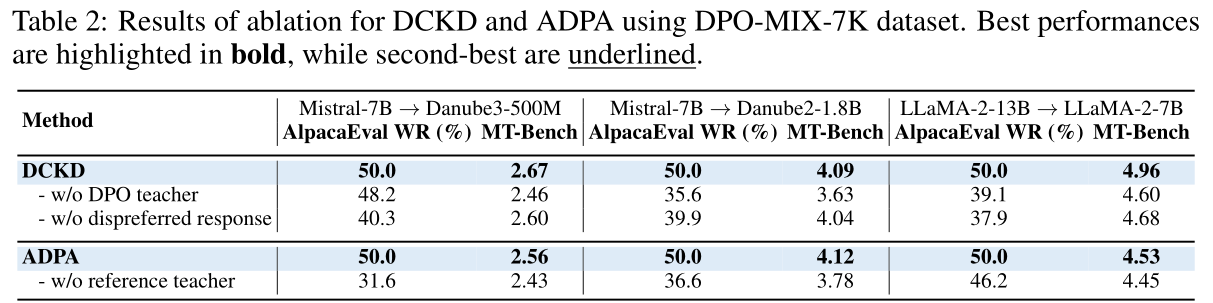
消融实验结果表明,DCKD中移除DPO教师会导致显著的性能下降,这表明在人类偏好数据上优化的DPO教师能更好地与人类偏好对齐,并为学生模型提供更强的指导。此外,从DCKD中排除非偏好响应会导致显著的性能下降。这一结果突出了非偏好响应的重要性,它帮助学生模型不仅理解偏好行为,还理解不良行为,从而更好地与人类偏好对齐。
对于ADPA,移除参考教师会导致严重的性能下降,这些结果突出了优势函数的关键作用,它提供了DPO教师概率之外的基本指导。
文章提出了一个教师-学生框架,利用一个已经与人类偏好良好对齐的LLM作为“教师模型”,来指导未对齐的SLM“学生模型”的学习过程。
在此框架下,论文主要贡献了两种新的对齐方法:
双约束知识蒸馏(Dual-Constrained Knowledge Distillation, DCKD):这是一种直接的方法,通过知识蒸馏将偏好知识从对齐的教师模型转移到学生模型。它通过引入两个KL散度约束来捕获教师模型对偏好和非偏好响应的预测行为,从而同时考虑积极和消极信号。
优势引导蒸馏偏好对齐(Advantage-Guided Distillation for Preference Alignment, ADPA):为了克服DCKD在区分偏好和非偏好响应方面的局限性,ADPA引入了一个更细粒度的偏好对齐机制。它利用从DPO(直接偏好优化)训练的教师模型和参考教师模型中导出的“优势函数”,为学生模型提供分布级别的奖励信号。这种优势函数量化了教师模型对每个动作的相对偏好,从而提供更细致的指导,并缓解了传统强化学习中稀疏奖励信号的问题。
主要发现和结果:
实验结果表明,DCKD和ADPA都显著提高了SLM的对齐能力,并缩小了与大型模型的性能差距。
ADPA表现出卓越的性能。
将ADPA与DCKD结合使用(称为ADPA+)能够实现更大的对齐改进,因为它允许学生模型更好地捕获教师的输出分布,并在训练期间学习细微的偏好信号。
论文还通过理论分析和实证结果表明,ADPA的“分布级优势”机制相比于传统的token级或序列级奖励,具有更低的样本复杂度(O(1)),从而确保了训练的稳定性和效率。
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
这篇文章探讨了强化学习(GRPO)有效性的深层原因
奖励排名微调RAFT(Reward-ranked Fine-Tuning)
该算法核心思想是利用奖励信号来筛选出高质量的样本进行微调。它不依赖复杂的强化学习算法,而是通过一个相对简单的三步流程来实现。
1.数据收集(“采样”发生在这里)
对于给定的一个批次的提示(prompts)
模型会为每个提示生成
n个候选响应这里的“采样”指的是LLM根据其当前的策略(即参数 πθ)生成多个不同的、可能的响应
2.数据排名(拒绝采样)
在生成了每个提示的
n个候选响应之后,会使用一个二元奖励函数 r(x,a) 来评估每个响应的质量。这个函数会为每个提示-响应对分配一个标量反馈。拒绝采样的含义是:对于每个提示,我们只保留那些获得了最高奖励的响应(通常是 r=1 的响应)。所有获得较低奖励(例如 r=−1)的响应都会被“拒绝”,即被丢弃,不用于后续的训练。
最终,所有这些被保留下来的“正样本”(即高质量的提示-响应对)会被聚合到一个新的数据集 D 中。
3.模型微调
在完成了数据收集和拒绝采样步骤后,我们得到了一个只包含高质量(正奖励)样本的数据集 D。
当前的LLM策略(πθ)会在这个筛选出的数据集 D 上进行微调。微调的目标是最大化这些高质量样本的对数似然。
这意味着模型会学习如何更好地生成那些被判定为“正确”或“高质量”的响应。
本文研究表明,RAFT 这种简单、基于拒绝且仅依赖正奖励样本的方法,出人意料地成为一个强大的基线,其性能优于或媲美 PPO 和迭代 DPO 等更复杂的方法。我们通过引入重要性采样和剪裁进一步改进了 RAFT,从而得到了 RAFT++,它在保持简单稳定训练流程的同时,实现了接近最先进的性能。
通过广泛的消融实验,我们发现 GRPO 的主要优势并非来自其奖励归一化,而是来自丢弃所有正确和所有不正确响应的提示。基于这一洞察,我们提出了 Reinforce-Rej,这是一个最小的策略梯度变体,它过滤掉所有不正确和所有正确的样本。Reinforce-Rej 提高了 KL 效率和熵稳定性,突出了探索在基于奖励的微调中的作用。
未来的方法不应仅仅依赖原始的负反馈,而应考虑更具选择性和原则性的机制来纳入样本质量。
Between Underthinking and Overthinking- An Empirical Study of Reasoning Length and correctness in LLMs
论文通过实证研究探讨了LLMs推理长度与推理正确性之间的关系,分析了过度思考和思考不足两种极端情况的影响
研究发现,推理长度与正确性之间存在非线性关系,存在一个最优推理长度范围,在这个范围内LLMs能够取得最佳的推理性能。论文提出了多种方法来确定最优推理长度,并设计了动态调整推理策略的框架,以在不同任务中实现最佳性能
本文采用两种视角研究LLM推理行为:
样本级别分析
定义:针对同一个输入问题,模型会生成多个不同的响应(或称“样本”)。样本级别分析就是研究这些针对同一个问题的不同响应(样本)之间,它们的推理长度和正确性之间的关系
目的:旨在精确评估生成长度对正确性的影响,同时保持其他因素(如问题本身的难度)不变
问题级别分析
定义:这种分析是针对每个问题整体的平均推理长度和其整体正确性(在多个样本上的平均表现)之间的关系。
目的:旨在理解为什么不正确的响应通常更长,以及模型是否能识别并适应不同难度的问题。
Reasoning Models Can Be Effective Without Thinking
这篇文章探讨了大型语言模型(LLMs)在推理任务中是否必须经过冗长的“思考”过程。研究发现,通过一种名为 NoThinking 的简单提示方法,即绕过显式思考过程,其效果出人意料地好。
主要发现包括:
NoThinking 的有效性: 尽管移除了思考框,NoThinking 在控制令牌数量的情况下,在七个具有挑战性的推理数据集上表现优于或与传统的“Thinking”方法(包含显式思考过程)相当。尤其是在低预算设置中,NoThinking 的表现显著更优。
pass@k 性能: 随着
k值的增加(即尝试的样本数量增加),NoThinking 的pass@k性能变得更具竞争力,并且在大多数情况下始终优于 Thinking。并行扩展: 基于 NoThinking 在
pass@k方面的优势,研究者提出了一种并行扩展方法,即独立生成N个 NoThinking 输出并进行聚合。这种方法在相似或显著更低的延迟下,实现了比传统顺序推理更好的准确率。效率提升: 对于有完美验证器(如形式定理证明)的任务,NoThinking 结合并行扩展可以在相似准确率下,将总令牌使用量减少高达4倍,并降低7倍延迟。对于没有验证器的任务,即使使用简单的基于置信度的选择策略,NoThinking 也能在多数低令牌预算基准测试中优于 Thinking,甚至在 OlympiadBench (Math) 上实现了更高的准确率和9倍的延迟降低。
(但是设置了Budget相当于强行打断了模型的思考步骤,这点比较怪异,正确率估计不如完全思考的高。并且NoThinking的优势体现在k值很大的时候,但是这无疑是种浪费)