论文阅读(1)——奖励替代/无监督/半监督强化学习
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
Policy-labeled Preference Learning: Is Preference Enough for RLHF?
One-shot Entropy Minimization
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
这篇论文的核心在于解决强化学习(RL)应用于大语言模型(LLMs)推理时策略熵急剧下降的问题。在没有特殊干预的情况下,LLM的策略熵在RL训练的早期阶段会迅速下降到接近零,导致模型变得过于“自信”而缺乏探索能力,进一步导致了策略性能的饱和,难以进一步提升。
【策略熵】——量化了代理选择动作时固有的可预测性或随机性
高熵意味着模型在众多可能的动作(token)中选择时犹豫不决,有更多的探索倾向,会尝试更多不同的路径和解决方案。这对于在复杂、未知的环境中寻找最优解至关重要。
低熵表示模型对某个动作(token)非常确定,倾向于重复已知的、被认为“最好”的行为,探索性很弱。
文章主要发现和贡献:
熵崩溃与性能饱和的可预测关系:
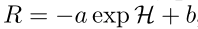
这意味着性能的提升是以牺牲探索能力(熵)为代价的,并且存在一个可预测的性能上限(当熵为0时)
熵动态的理论分析:为了理解熵崩溃的深层机制,论文从理论上分析了策略熵的动态变化。他们发现,策略熵的变化是由动作概率和logits变化之间的协方差驱动的,在使用策略梯度算法时,这与动作的优势成比例。具体来说,高概率且高优势的动作会降低策略熵,而低概率但高优势的动作会增加策略熵。实证验证也支持了这一理论。
基于协方差的熵控制方法:鉴于高协方差的token是导致熵崩溃的主要原因,论文提出了两种简单而有效的技术来控制熵
Clip-Cov:通过裁剪(detach gradient)部分具有高协方差的token的梯度更新
KL-Cov:对具有最高协方差的token施加KL散度惩罚
Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
论文提出一种名为“熵最小策略优化”(EMPO)的强化学习算法,核心思想是通过持续最小化LLM在潜在语义空间中的预测熵,来激励其推理能力,而无需任何外部监督。
现有方法及局限性:
实验结果表明,EMPO 在数学推理和自由形式自然推理任务上均取得了与有监督方法相竞争的性能,显著提升了 Qwen2.5-Math-7B 和 Qwen2.5-7B Base 模型的准确率。论文还深入探讨了 RL 后训练对 LLM 推理能力的本质影响,认为其主要在于提升模型访问和选择预训练中已存在的推理模式的效率,而非创造全新的推理能力。
(说人话就是认为LLM的预训练赋予了LM的所有能力,微调和训练则是为了有效激发和引导这些现有技能)/(强化学习并不会改变LLM固有的推理能力,表明了基本推理途径在很大程度是预先存在的。RL和本文提出的EMPO,主要是改进模型有效访问、优先排序和一致选择这些潜在推理模式的能力,而不是灌输基本的新模式。 所以改进已有LLM主要是引导LLM去使用这些技能(在训练的过程中已经存在了))
EMPO的创新点在于:
完全无监督的学习范式:EMPO 是首次尝试实现完全无监督的 LLM 推理能力激励。它摆脱了对任何形式外部监督信号的依赖,包括人工标注的推理轨迹、验证过的黄金答案或预训练的奖励模型。这大大降低了数据收集的成本和复杂性,提高了方法的可扩展性
语义熵作为内在奖励: EMPO 创新性地将语义熵作为一种内在奖励信号来指导强化学习过程。它不评估输出的对错,而是通过促使模型生成语义上更一致的答案来优化其策略,从而间接提升了推理的可靠性和准确性
熵阈值策略: 为了缓解无监督优化可能带来的奖励作弊风险,EMPO 引入了简单的熵阈值策略,只对具有适度不确定性的提示进行优化,过滤掉熵过高(高度不确定)或熵过低(可能过度自信)的答案,从而稳定了训练过程
语义熵的定义:
在论文中,语义熵(Semantic Entropy)是经典香农熵在大型语言模型领域的自然延伸,用于衡量模型输出在语义层面的不确定性。

Policy-labeled Preference Learning: Is Preference Enough for RLHF?
文章主要内容总结
这篇论文《Policy-labeled Preference Learning: Is Preference Enough for RLHF?》提出了一种名为策略标记偏好学习(Policy-labeled Preference Learning, PPL)的新型强化学习框架,旨在改进人类反馈强化学习(RLHF)在复杂环境和离线数据中的表现。
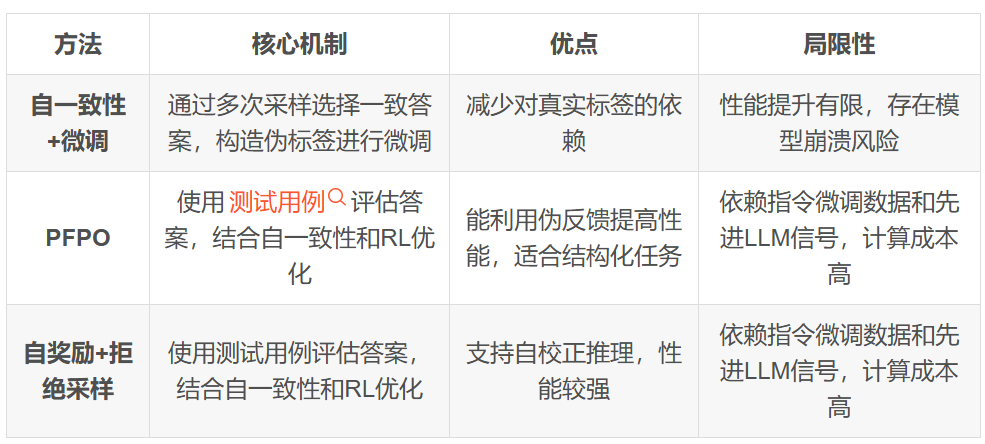
传统的RLHF方法,特别是像DPO(直接偏好优化)这样的方法,在处理具有环境随机性和由多样化行为策略生成的离线数据时,存在一个关键的“似然不匹配”问题。它们往往错误地假设所有轨迹都由最优策略生成,导致无法准确区分轨迹表现好坏是源于行为策略的次优性还是环境的随机性。这在离线RL中尤为突出,因为数据是固定的且行为策略通常未知,导致学习效率低下和次优结果。此外,在稀疏奖励环境中,传统方法难以获得有效的学习信号。
论文提出了策略标记偏好学习(PPL)。PPL的核心思想是:
基于遗憾(Regret)的偏好建模: 遗憾被定义为最优策略预期回报与行为策略实际回报之间的差距。与奖励总和或最优优势不同,遗憾能够更精细地量化行为策略的次优程度,即使在稀疏奖励环境下也能提供有意义的反馈。论文论证了遗憾是相对于给定最优策略唯一定义的,且内在数学特性良好。
明确标记行为策略: PPL在处理轨迹时,会明确考虑生成该轨迹的“行为策略”信息。在离线数据集中,即使行为策略未知,PPL也会尝试分配伪标签来近似。
对比KL正则化: 引入了对比KL正则化项,该项将学习到的策略与偏好轨迹的生成策略对齐,同时使其偏离非偏好轨迹的生成策略,进一步优化学习过程。
PPL通过将行为策略信息直接纳入学习过程,并利用基于遗憾的偏好建模,实现了对环境随机性和行为策略次优性影响的解耦。这意味着PPL能够更准确地判断轨迹表现好坏的根本原因,从而避免了似然不匹配,并能从复杂、可能次优的离线数据中更有效地学习到符合人类偏好的策略。
实验表明,PPL在MetaWorld基准测试的同质和异质离线数据集上均表现出强大的性能,优于现有基线方法,并展示了对数据集变化的鲁棒性。此外,PPL在在线RLHF设置中也表现出高效性,能够作为一种有效的在线DPO算法,在参数量更少的情况下达到与现有方法相当的性能。
【传统方法DPO】
在传统的RLHF中,轨迹生成过程通常是:
初始策略(Initial Policy): 首先会有一个初始的策略(通常是一个预训练的语言模型,通过监督微调SFT得到)。这个策略定义了在给定某个状态(例如一个提示)时,智能体应该采取什么动作(例如生成什么文本)。
与环境互动: 智能体(由当前策略控制)与环境进行互动。对于语言模型,这个“环境”就是生成文本的过程;对于机器人,则是物理世界。智能体根据其当前策略选择动作,然后环境根据这些动作更新状态。
收集轨迹: 在这个互动过程中,智能体会记录下它所经历的每一个状态和采取的每一个动作,从而形成一条完整的轨迹。
传统RLHF方法在学习奖励汉化或直接优化策略时,往往隐式地假设所收集到的轨迹,即使是由当前(可能次优的)行为策略生成的,也能够被解释为某种程度上反映了“最优”行为。
(可能“盲目”地认为所有观察到的“好”轨迹都应该由最优策略生成,而忽略了实际生成这些轨迹的策略可能并非最优,且环境随机性可能影响结果)
One-shot Entropy Minimization
解决了什么问题-如何解决问题-为什么能解决问题
一、研究背景:为什么单样本熵最小化如此重要
LLM的RL准备过程非常麻烦,通常需要:
大量高质量的真实标记数据
精心设计的基于规则的奖励
相比之下,熵最小化(EM)是完全无监督的,可以提高模型在面对问题时的确定性(自信度),而无需任何外部反馈。
Ubiquant的研究团队进行了一项史无前例的大规模实验,训练了13,440个大型语言模型,以消除训练中的随机性,确保实验结果和观察到的模式具有可靠性。他们的研究表明,仅使用一个未标记数据,性能就已经超过了传统的强化学习。而且,它们通常在短短10个训练步骤内就能收敛,这比强化学习通常需要的数千步要快得多。
熵最小化基于两个假设:
大型语言模型的生成中的采样过程本质上是随机的
正确答案通常比错误答案具有更低的熵(更确定、更集中的概率分布)
研究表明,EM和RL具有相同目标:在不添加新知识的情况下释放预训练模型的潜在能力。而两者都依赖“token重新排序”的过程,以最大限度地提高模型的性能。
二、方法:单样本熵最小化
1.熵最小化算法
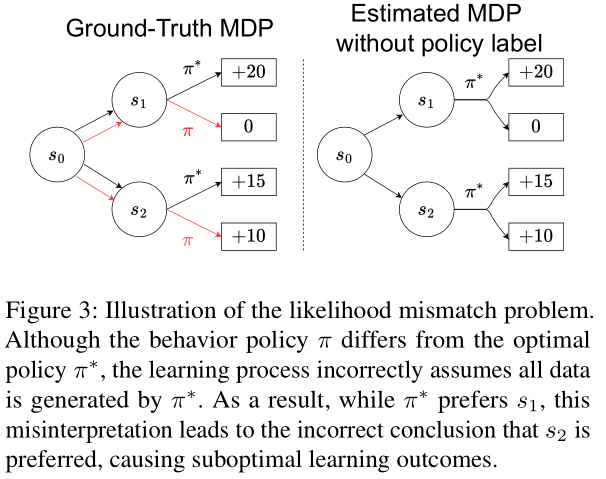
熵最小化就是这样一个过程:它让语言模型在生成回答时,更加"确定"自己的选择,减少不确定性。具体来说,对于预训练的自回归语言模型,参数为θ,给定输入提示x(如问题或问题描述),模型会自回归地生成响应序列。
在每一步生成时,模型计算下一个词的条件熵:
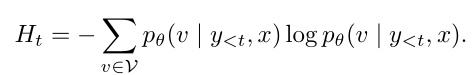
单个输入x的整体熵最小化损失函数为:
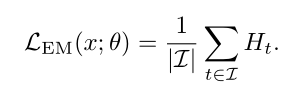
2.数据选择策略
熵最小化依赖于一个前提:模型的预测不确定性可以作为有意义的训练信号。但并非所有输入提示都同样有信息量。
本论文采用了一种基于方差的数据选择策略。具体来说,他们测量模型pass@k准确率的方差(即模型在多次尝试下表现的波动程度),并选择模型表现方差最大的提示。这样做的目的是针对那些处于模型能力边缘的输入——既不太简单也不太困难——使它们成为熵驱动优化的理想目标。
(低方差表示模型要么非常确信正确答案,要么非常确信错误答案,这两种情况对熵最小化都不理想,因为它们导致低熵后验,无法进一步改进。)
数据选择目标函数定义为:
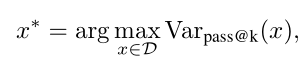
三、为什么单样本熵如此有效
1.Logits移位
模型对每个可能的token有一个“确信度分数”,被称为Logits。
本文从NuminaMath数据集中抽取20个提示,使用四种不同模型生产响应
Qwen2.5-Math-7B
Qwen2.5-Math-7B-EM
Qwen2.5-Math-7B-RL
Qwen2.5-Math-7B-EM-RL
对于每个输出,他们提取了logits,这些是模型在应用softmax函数之前产生的未归一化分数。
分析表明,经过熵最小化训练的模型,其logits分布的偏度显著增加,表明分布向右偏移。
相比之下,经过强化学习训练的模型显示出logits偏度的明显减少,表明分布向左偏移。
这种现象被称为Logits移位,右移的logits对大型语言模型的生成和采样过程是有益的,因为模型主要从高概率token中采样。将logits向右移位会增加候选token的数量并扩展高概率路径,从而增强模型能力。相反,左移的logits被认为对大型语言模型的生成过程有害
2.训练损失与推理性能的关系
在实验中,约在第10步训练时,熵最小化的训练损失降到较低水平,模型在数学推理方面的性能达到峰值。然而,当熵最小化训练损失在第10步之后继续下降时,数学推理性能开始下降。
研究团队认为熵最小化主要作为一种塑造模型分布的工具,而不是作为一种学习方法或策略。因此,分布塑造的效果在很少的训练步骤内就基本达成,导致熵最小化训练损失的持续下降与数学推理性能提升之间的解耦。
3.温度参数的影响
在LLM中,“温度”参数控制着生成文本的多样性和确定性。高温度会使模型生成更多样化但可能更不精确的文本,低温度则会使模型生成更确定但可能缺乏创造性的文本。
研究发现,随着生成温度的增加,熵最小化训练模型在四个数学推理基准测试中的平均性能总体上呈上升趋势。平均性能的最大值最初增加,然后在温度约为0.5时下降。更高的温度导致更好的平均推理能力,而中等温度(如0.5)导致更大的性能方差,从而创造更高峰值性能的机会。
4.EM在RL前后的效果
在强化学习之后应用熵最小化导致在四个数学基准测试中的性能稳步下降,而在熵最小化之后应用强化学习则产生持续的收益。这表明熵最小化加剧了强化学习引入的分布扭曲,强化了强化学习的"对齐税"