大模型入门(3)——学习OpenRLHF框架
在此之前先查看了一下自己电脑的基础配置:
系统:
操作系统:Windows 11 家庭中文版64位
处理器:12th Gen Intel(R) Core(TM) i9-12900HX 2.30 GHz
机带RAM:16.0 GB (15.7 GB 可用)
显卡1:
芯片类型:Intel(R) UHD Graphics Family
总内存:8184MB
显示内存(VRAM):128MB
共享内存:8056MB
显卡2:
芯片类型:NVIDIA GeForce RTX 4060 Laptop GPU
总内存:16013MB
显示内存(VRAM):7957MB
共享内存:8056MB
OpenRLHF框架介绍
OpenRLHF是第一个基于Ray、vLLM、ZeRO-3和HuggingFace Transformers构建的开源高性能RLHF框架,旨在让RLHF训练变得简单易用:
基于Ray的分布式架构
OpenRLHF利用Ray实现高效的分布式调度。它将Actor、Reward、Reference和Critic模型分布到不同的GPU上,支持高达70B参数模型的训练
它还支持 Hybrid Engine 调度,允许所有模型和 vLLM 引擎共享 GPU 资源,最大限度地减少空闲时间并提高 GPU 利用率
vLLM 推理加速 + AutoTP
RLHF 训练中 80% 的时间都花在样本生成阶段。基于 vLLM 和自动张量并行 (AutoTP),OpenRLHF 提供高吞吐量、内存高效的推理。与 HuggingFace Transformers 的原生集成确保了无缝且快速的生成,使其成为目前最快的 RLHF 框架
基于 ZeRO-3 / AuoTP 的内存高效训练
基于 DeepSpeed 的 ZeRO-3, deepcompile 以及 AutoTP,OpenRLHF 无需重量级框架即可实现大模型训练。它直接与 HuggingFace 配合使用,方便加载和微调预训练模型
优化的PPO实现
尝试复现RLHF的训练流程
参考文章:“如何正确复现 Instruct GPT / RLHF?”
1.GPT——自回归语言模型,利用句子前面的单词预测后面的单词。
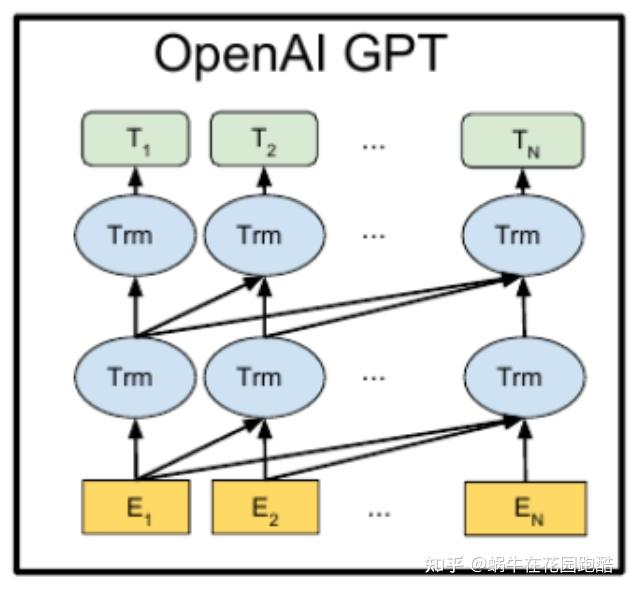

2.Instruct GPT——仅仅通过预训练的GPT不会遵循人类的意图回答问题,此时通过监督微调(SFT)/人类反馈强化学习(RLHF)来进一步微调(finetune)模型。
Insruct GPT的训练流程可以分为三个阶段:
监督微调(SFT)-> 奖励模型训练 -> PPO训练,后面两个阶段是常说的RLHF
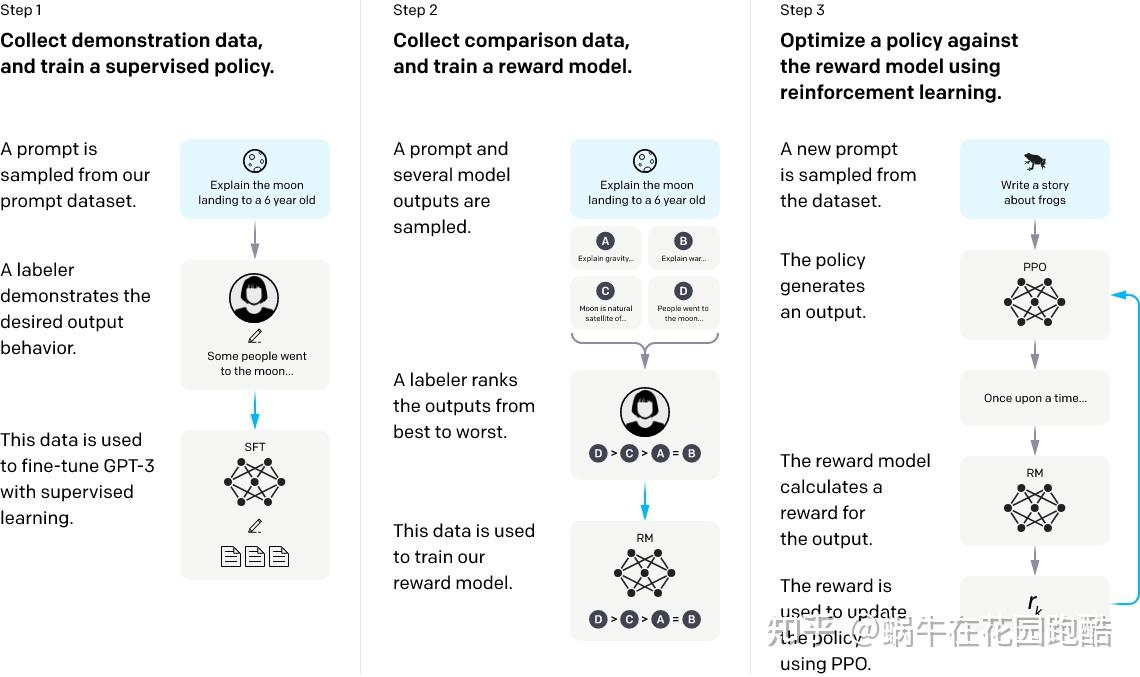
SFT:这些“提示-示范输出”的数据对(prompt-demonstration output pairs)被用来通过监督学习(Supervised Learning)对一个基础的GPT-3模型进行微调(fine-tune),从而得到一个“监督微调模型”(SFT,Supervised Fine-Tuning)。这个SFT模型就是我们的初步策略
训练奖励模型:
Instruct GPT 中使用 pair-wise 排序损失函数来训练一个 Reward Model,如下:

这些“提示-排序结果”的数据被用来训练一个奖励模型(Reward Model, RM)。这个奖励模型的目标是学习如何评估一个给定输出的质量,它会为每个输出分配一个分数,并且这个分数应该与人工排序的结果一致
【EOS_token】:从实现细节上来说,我们假定使用 GPT 模型作为这个奖励模型的基础架构,那么我们有多种思路来预测一个对话的奖励值。
1.对所有token上预测reward取平均
2.在最后一个token,即EOS_token上预测reward
这里我们倾向于方式2,因为对于GPT这种模型,只有EOS_token的输出才能看完整句话给出一个整体的评价。这种方式也在 Anthropic 的相关论文中被使用
如何进行PPO训练
(1)MDP
对于一个会话模型,可以以两种不同角度建模为强化学习问题。
第一种即 Token-level MDP,简单地说每个单词都作为一个独立动作,将 GPT 模型的自回归预测单词的过程建模为一个长度等于句子长度的 MDP 问题。这种场景下对应于RL中的Single-agent问题,下面是严格的数学定义:

第二种可以称为 Multi-agent MDP,即将GPT模型的输出一整句话为建模为多个智能体,即Multi-agent问题,每个输出的单词都是一个独立的智能体。这场情况下,我们只有一个长度为1 的Multi-agent MDP。即状态等于 x,动作等于 y (注意y是一个动作序列)。
TRLX/DeepspeedChat等方案使用Token-level MDP,而ColossalAI Chat/PaLM-rlhf-pytorch使用Multi-agent的建模策略。这里我们倾向于使用第一种,即Token-level MDP。理由是:1. OpenAI 早期开源的 RLHF 实现均使用 Token-level MDP; 2. 大量的论文比如 ILQL/RL4LMs 也是使用Token-level MDP;3. Multi-agent 问题的求解目前仍处于学术研究状态,并不像Single-agent那么成熟。
从PPO的实现细节上来看,Token-level MDP 的 Critic 网络输出 Value 应该和 Actor 中输出单词一一对应,等价于Single agent 的PPO 算法,并且用GAE来估计advantage;而 Multi-agent MDP 只需要用一个 Centralized Critic 输出一个共享的 Value,对应于 MARL中的 MAPPO 算法,由于Multi-agent MDP只有1步就结束了,不需要用GAE估计advantage。
(2)PPO-ptx
Instruct GPT 中的 PPO-ptx 损失函数分为三部分,第一项为 Reward 模型给出的奖励,第二项为 KL reward 用于约束当前策略和初始策略(SFT训练后的策略)的距离,第三项为 pretrain loss (PTX loss),用于避免策略遗忘预训练阶段学习到的知识。

a.Reward
第二项的 KL reward前面有一个系数 beta,从实际训练的体验来说 beta的设置非常重要,可以有效避免策略走的太远(走太远容易导致策略过拟合和坍塌),这里beta的设定通常要结合target KL的设定,即我们可以通过实验确定KL变化多大模型的表现比较好,然后根据这个 target KL来决定 beta的大小,但是这种方式通常需要大量的实验比较。
不过我们可以从 OpenAI的早期论文 (https://arxiv.org/pdf/1909.08593.pdf) 中找到一种根据 KL_target 自适应调节 beta的算法,这个方法已经被 TRLX/TRL实现。

b.PTX Loss
最后一项是预训练的 Loss,同样这一项有一个系数 gamma,InstructGPT 将 gamma设为 27.8
(3)Reward Normalization
在 PPO 的训练中,我们通常会使用 reward normalization 以及 value normalization 等类似技术,我们发现在 RLHF 的训练中 reward normalization 非常有助于训练的稳定性,毕竟我们的 reward 不像在游戏环境中那么规则,而是通过一个模型学出来的中间层输出(这就意味着输出范围可能会很大)。
(4)Distributed Advantage Normalization
同样 Advantage Normalization 也是PPO训练种常用的稳定训练的技术,我们在使用 DeepSpeed 等类似 DDP 的训练手段时应注意做全局样本的 Advantage Normalization,而不是某个DDP进程只针对自己的样本做归一化。这一点目前的 RLHF 开源框架都没有充分考虑进来。
RLHF有什么作用
1.有一些LLM需要的目标函数是难以通过规则定义的,比如说什么是“无害性”,“有帮助性”,如果我们希望模型最后具有这些好的特性,就需要制定这样的训练目标函数,而用人类的偏好学习一个reward model再用RL来训练,就自然的可以将这些特性融合到LLM里面。
2.RLHF可以泛化,在SFT阶段,人类的高质量样本确实很快速让模型align人类的意图,但是这些人类编写的样本始终是有限的。而对于RL,我们只要一个足够好的reward model 结合 RL的探索特性,就等于我们能有无穷的样本对模型 finetune(注意提示词 prompts是有限的,但RL的samples是无限的)
3.如果RM质量比较好,RLHF可以通过RL的探索特性找到比SFT更好的解 (即reward 比 SFT 样本更高的解)
最近 OpenAI 科学家 John Schulman 对 RLHF的作用提出了一些看法 [link]
1.多样性角度,对于SL,模型只要稍微偏移答案就会收到惩罚,而RL对于多个回答可能有同样的reward,这和人类的行为是类似的
2.负反馈角度,监督学习里只有正反馈,而 RL 可以提供负反馈信号,人类学习的时候也是在失败中进步
3.自我感知角度,对于”知识获取型“问题,可分类两种情况:
(1)如果模型内部的知识图谱具有这个问题的知识,那么SFT会让其将知识和问题联系提来
(2)如果模型内部是没有这个知识图谱的,SFT容易让模型学会说谎。为了提升模型的可信度,我们倾向于想做的是模型直接回答不知道,而不是去记忆SFT的结论,因为这可能会让模型在遇到相关问题时胡编乱造(即模型的内部知识不理解这个问题,但是死记硬背了一个回答)。我们认为reward model和 actor是同一个基础模型,他们具有相同的内部知识系统,所以RM可以判断于自己不懂的问题回答不知道也给予奖励