大模型入门(7)——RAG
初步认识RAG
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。RAG模型由Facebook AI Research(FAIR)团队于2020年首次提出,并迅速成为大模型应用中的热门方案。
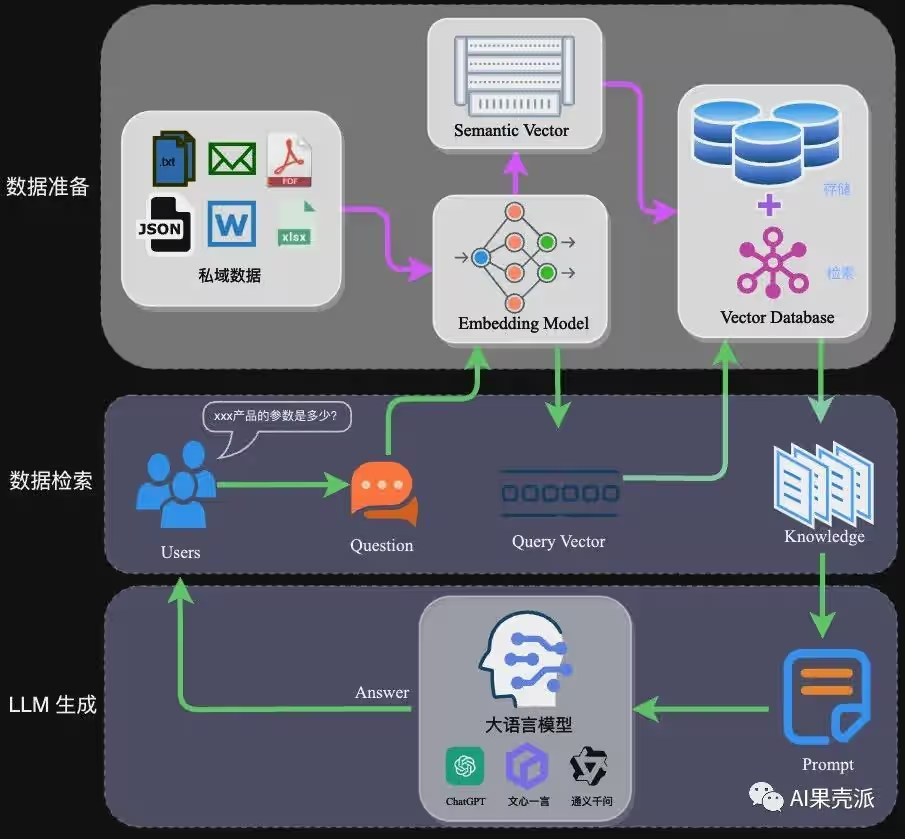
完整的RAG应用流程主要包含两个阶段:
数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
RAG文档解析工具
人工智能 - RAG 文档解析工具选型指南 - IDP技术干货 - SegmentFault 思否
对于 RAG 系统而言,从文档中提取信息是一个不可避免的情况。最终系统输出的质量很大程度上取决于从源内容中提取信息的效果。
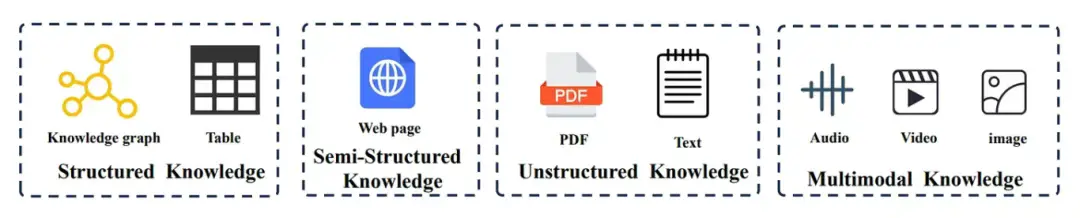
01 结构化知识:数据按规则组织的范式
1.1 知识图谱:易于查询,便于使用,难以集成
知识图谱以一种清晰、互联的方式描述实体及其关系,使其成为机器系统的图谱遍历与查询的理想选择。
RAG 系统非常喜欢这样的结构化数据源 —— 它们精确且语义丰富。但真正的挑战不在于查找数据,而在于如何有效地利用它。
如何从海量知识图谱中提取有意义的子图?
如何将结构化的图谱数据与自然语言对齐?
随着图谱规模的增长,系统是否仍能保持高效?
一些有前景的解决方案正逐步解决这些问题:
GRAG 从多个文档中检索子图,来生成更聚焦的输入。
KG-RAG 采用探索链算法(Chain of Explorations,CoE)来优化基于知识图谱的问答性能。
GNN-RAG 采用图神经网络(GNN)检索和处理来自知识图谱(KG)的信息,在数据输入大语言模型(LLM)之前先进行一轮推理。
SURGE 框架利用知识图谱生成更具相关性和知识感知(knowledge-aware)的对话,从而提升交互质量。
在特定领域,诸如 SMART-SLIC、KARE、ToG2.0 和 KAG[3] 等工具已充分证明,知识图谱作为外部知识源可以发挥多么强大的作用,可帮助 RAG 系统同时提升准确性和效率。
1.2 表格:结构紧凑、数据密集且解析困难
表格也是一种结构化数据 —— 但它们与知识图谱截然不同。几行几列就可能蕴含着大量信息。但如何让机器理解这些信息?那完全是另一回事了。
表格中未明示的逻辑关系、格式不一致、专业领域内特有的知识...表格数据常游走于秩序与混沌之间。幸运的是,已有专门处理此类复杂情况的工具:
TableRAG[4] 结合查询扩展(query expansion)、表结构与单元格检索(schema and cell retrieval),在将信息传递给语言模型前精准识别关键内容。
TAG 和 Extreme-RAG 则更进一步整合了 Text-to-SQL 能力,使语言模型能够直接“操作数据库”。
核心结论?若能有效解析表格,它们就是价值极高的信息源。
02 半结构化数据:HTML、JSON 以及网络数据的杂乱中间态
半结构化数据就像数据世界的“家中老二(middle child)” —— 既非完全结构化,也不完全是非结构化的。它比知识图谱更灵活,却比原始 PDF 文档更有条理。典型代表如 HTML 页面、JSON 文件、XML、电子邮件等格式,它们虽具备一定的结构特性,却常表现出结构规范不一致或结构要素不完备的特征。
尤其是 HTML,它无处不在,而每个网站都有其独特性。虽然存在 tags、attributes、elements(译者注:DOM 核心构件) 等结构化成分,但仍混杂着大量非结构化文本与图像。
为了有效解析 HTML,业界已开发出一系列工具和开源库,可将 HTML 内容转化为文档对象模型(DOM)树等结构化格式。值得关注的流行库包括:BeautifulSoup、htmlparser2、html5ever、MyHTML 以及 Fast HTML Parser。
此外,HtmlRAG[5] 等 RAG 框架在 RAG 系统中利用 HTML 格式替代纯文本,从而保留了语义与结构信息。
若希望 RAG 系统真正理解网页数据而非依靠胡编乱造 —— HTML 解析便是这一切的起点。
03 非结构化知识:PDF、纯文本(既杂乱又有内在逻辑)
接下来叙述的内容才是真正的挑战。非结构化数据(自由格式的文本、PDF 文档、扫描报告)无处不在。
尤其是 PDF 文档,简直就是噩梦:不一致的布局、嵌入内部的图像、复杂的格式。但在学术、法律和金融等领域它们不可或缺。那么,我们该如何让它们符合 RAG 系统的要求呢?
我们可以使用更智能的 OCR 技术、版面分析技术和视觉内容 - 语言融合技术:
Levenshtein OCR 和 GTR 结合视觉和语言线索来提高识别准确率。
OmniParser 和 Doc-GCN 专注于保留文档的结构。
ABINet 采用双向处理机制提升 OCR 系统的表现。
与此同时,一大波开源工具的出现使得将 PDF 转换为 Markdown(一种对 LLM 更友好的格式)的过程变得更加容易。有哪些工具?我基本都已经介绍过了!
GPTPDF[6] 利用视觉模型解析表格、公式等复杂版面结构,并快速转换为 Markdown 格式 —— 该工具运行高效且成本低廉,适合大规模部署。
Marker[7] 专注于清除噪声元素,同时还保留原始格式,因而成为处理研究论文和实验报告的首选工具。
PDF-Extract-Kit(MinerU 采用的 PDF-Extract-Kit 模型库[8])支持高质量内容提取,包括公式识别与版面检测。
Zerox OCR[9] 对每页文档进行快照处理,通过 GPT 模型生成 Markdown,从而高效管理复杂文档结构。
MinerU[10] 是一种综合解决方案,可保留标题/表格等原始文档结构,并支持受损 PDF 的 OCR 处理。
MarkItDown[11] 是一种多功能转换工具,支持将 PDF、媒体文件、网页数据和归档文件转为 Markdown。
04 多模态知识:图像、音频与视频数据一同入场
传统 RAG 系统专为文本数据而设计,因此在处理图像、音频或视频等多模态信息时往往力不从心。这就导致其回应常显得肤浅或不完整 —— 尤其当核心信息蕴含于非文本内容中时。
为应对这些挑战,多模态 RAG 系统引入了整合和检索不同模态的基本方法。其核心思想是将文本、图像、音频、视频等模态对齐到共享嵌入空间(shared embedding space),实现统一处理和检索。 例如:
CLIP 在共享嵌入空间中对齐视觉与语言模态。
Wav2Vec 2.0 和 CLAP 专注于建立音频与文本的关联。
在视频领域,ViViT 等模型专为捕捉时空特征而设计。
这些技术都是基础模块。随着系统的不断演进迭代,我们将看到能够一次性从文档、幻灯片及语音内容中提取洞见的 RAG 应用。
Vtuber项目中的RAG实现
RAG系统架构概览
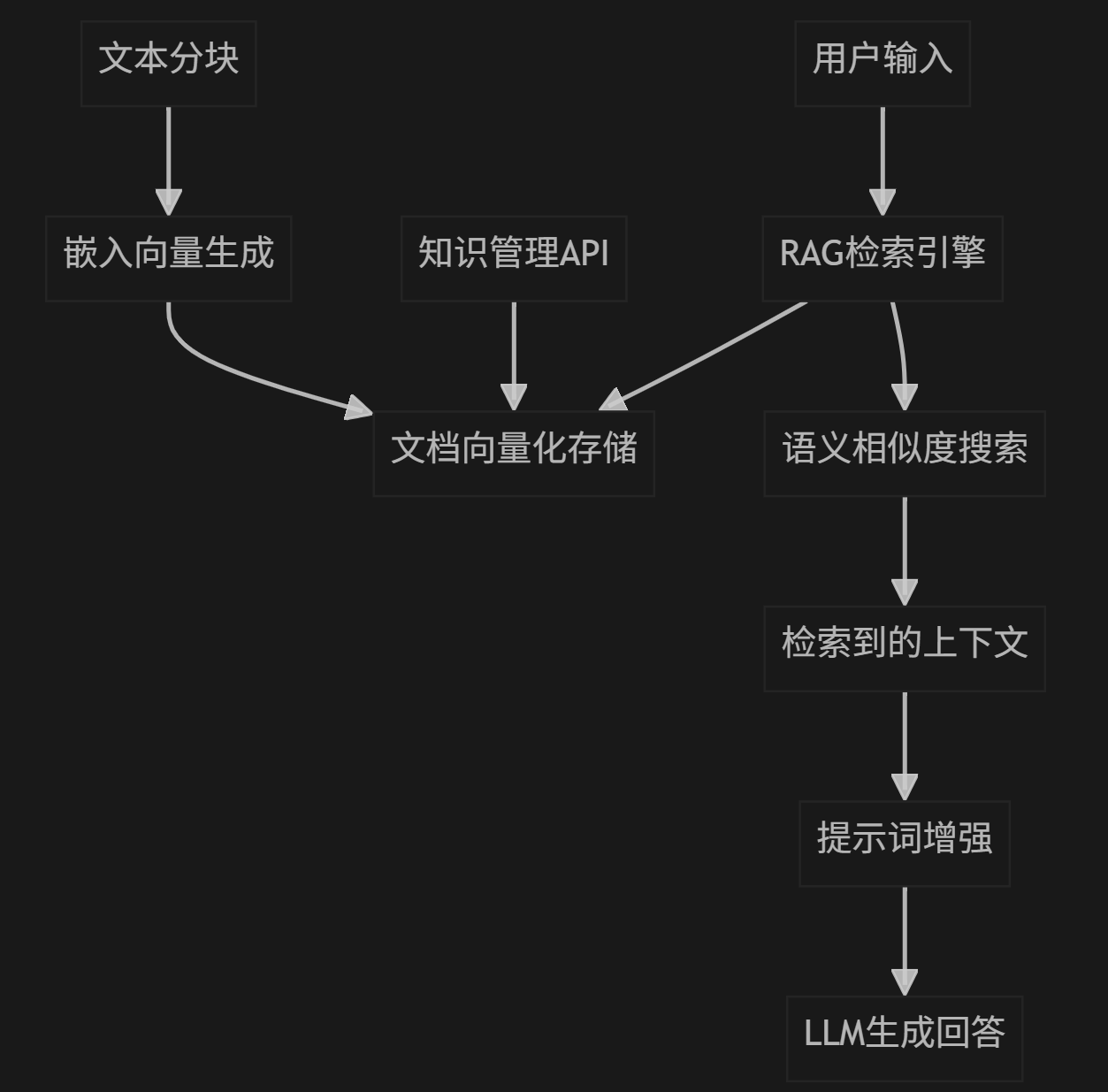
RAG核心流程
1.文档预处理 : 分块→向量化→存储
2.查询处理 : 向量化→相似度计算→排序
3.上下文构建 : 检索Top-K→合并→注入提示
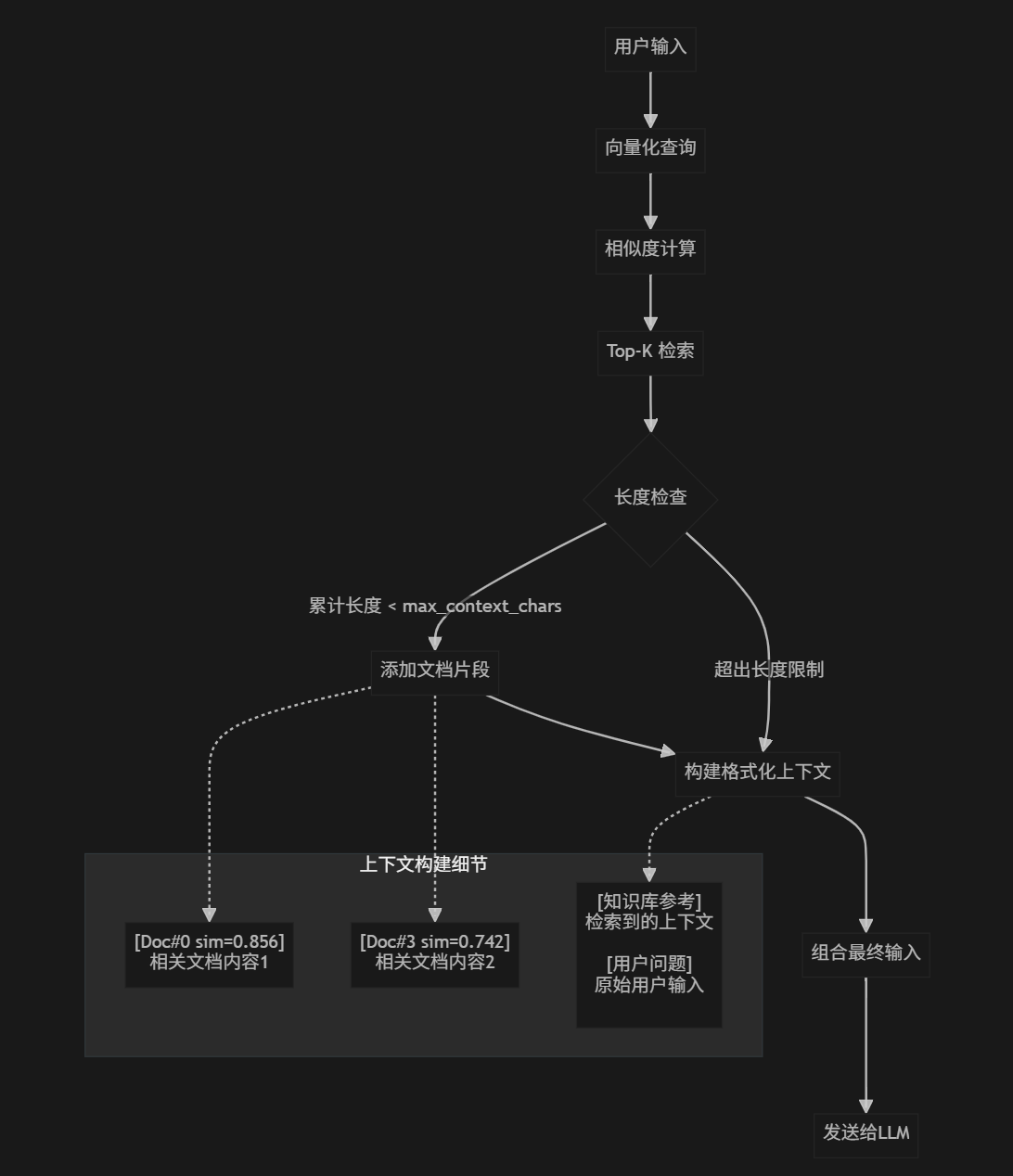
4.生成回答 : 增强提示→LLM推理→返回结果
核心代码结构
1.主引擎 - rag_engine.py
这是RAG系统的核心,包含完整的检索增强生成逻辑
核心组件解析
1.配置类
@dataclass
class EmbeddingProviderConfig:
base_url: str # 嵌入模型API基础URL
api_key: str # API密钥
model: str # 模型名称2.余弦相似度计算
def _cosine_similarity_matrix(a: np.ndarray, b: np.ndarray) -> np.ndarray:
a_norm = a / (np.linalg.norm(a, axis=1, keepdims=True) + 1e-10)
b_norm = b / (np.linalg.norm(b, axis=1, keepdims=True) + 1e-10)
return a_norm @ b_norm.T3.数据存储设计
文本存储:JSON格式(meta.json)- 存储原始文本和元数据
向量存储:NumPy格式(embeddings.npy)- 存储高维向量
分离设计:便于查看文本,高效存储向量
4.智能文本分块
def chunktext(self, text: str) -> List[str]:
# 滑动窗口分块:chunk_chars 大小,chunk_overlap 重叠
# 优点:保持上下文连续性,避免重要信息被截断5.嵌入向量生成
async def _embed_texts_local(self, texts: List[str]) -> np.ndarray:
"""使用本地模型生成文本向量"""
try:
import asyncio
# 在线程池中运行,避免阻塞事件循环
loop = asyncio.get_event_loop()
embeddings = await loop.run_in_executor(
None,
self._local_model.encode,
texts
)
return np.array(embeddings, dtype=np.float32)
except Exception as e:
logger.error(f"Local embedding failed: {e}")
raise6.核心检索算法
async def search(self, query: str, top_k: Optional[int] = None) -> Tuple[str, List[Dict]]:
"""搜索相关文档"""
if not query or self._embeds is None or not self._texts:
return "", []
qv = await self._embed_texts([query])
sims = _cosine_similarity_matrix(qv, self._embeds)[0]
k = min(top_k or self.top_k, len(self._texts))
idx = np.argsort(-sims)[:k]
ordered = [(int(i), float(sims[i])) for i in idx]
ctx_parts: List[str] = []
ctx_metas: List[Dict] = []
acc_len = 0
for i, score in ordered:
text = self._texts[i]
meta = self._metas[i] if i < len(self._metas) else {}
part = f"[Doc#{i} sim={score:.3f}]\n{text}"
if acc_len + len(part) > self.max_context_chars and ctx_parts:
break
ctx_parts.append(part)
ctx_metas.append({"index": i, "score": score, **meta})
acc_len += len(part)
return "\n\n".join(ctx_parts), ctx_metas2.对话集成 - single_conversation.py
rag_engine = getattr(context, "rag_engine", None)
if rag_engine:
try:
ctx_text, ctx_meta = await rag_engine.search(input_text)
if ctx_text:
logger.info(
f"RAG retrieved {len(ctx_meta)} chunks; augmenting user input."
)
input_text = (
f"[知识库参考]\n{ctx_text}\n\n[用户问题]\n{input_text}"
)
except Exception as e:
logger.error(f"RAG retrieval failed: {e}")非侵入性: 不影响原有对话流程
可选性: RAG 可以开启/关闭
透明性: 用户看不到检索过程,体验自然
3.服务上下文管理 - service_context.py
await self.init_rag(self.character_config.rag_config)
logger.debug(f"Loaded service context with cache: {character_config}") async def init_rag(self, rag_config: Optional[RAGConfig]) -> None:
"""Initialize or update the RAG engine if configured."""API接口层 - routes.py
@router.post("/rag/add-text") # 添加文本到知识库
@router.post("/rag/add-file") # 上传文件到知识库
@router.post("/rag/clear") # 清空知识库
@router.get("/rag/stats") # 获取知识库统计核心优势
轻量级设计
无需外部向量数据库 (如Pinecone、Weaviate)
基于 NumPy + JSON 的本地存储
适合中小型应用快速部署
模块化架构
text
RAGEngine (核心)
├── 文本分块 (_chunk_text)
├── 向量化 (_embed_texts)
├── 相似度计算 (_cosine_similarity_matrix)
├── 检索排序 (search)
└── 持久化存储 (_save_index/_load_index)
异步并发支持
所有I/O操作都是异步的
支持高并发的嵌入API调用
非阻塞的文件操作
多API兼容性
OpenAI兼容接口 (标准化)
千帆原生API (性能优化)
可扩展其他嵌入服务
核心指令
1.测试上传文件
curl -s -X POST http://127.0.0.1:12393/rag/add-file \
-F "file=@/Data/wyh/dc-avatar-server/rag_test_doc/filename.docx"2.查看索引统计
curl -s http://127.0.0.1:12393/rag/stats3.清空索引
curl -s -X POST http://127.0.0.1:12393/rag/clearVtuber项目中RAG文档解析工具的不足
截至2025.8.26,该项目的RAG文档解析工具是自己编写的,仅支持:
1.txt - 纯文本文件
2.md - Markdown文档
3.json - JSON格式文件
2025.8.26上午
接下来的工作是借助第三方库,让RAG支持PDF、Word、Excel等常见办公文档,还有Html网页解析
以下是修改项目时弄的文档:
2025.8.26下午
完成了pdf和docx文件的解析功能,今天就到这吧,得做点别的事情放松一下
Debug
1.依赖安装在vtuber环境中,项目用uv run run_server.py指令跑,发现缺少依赖包
原因是uv会用自己的隔离环境,忽略conda的安装,所以要把依赖写进项目依赖并由uv管理:
- uv add python-docx readability-lxml beautifulsoup4 charset-normalizer pymupdf
然后同步环境并重启服务:
uv pip sync requirements.txt
uv run run_server.py --verbose
两个包管理口径(conda/uv)混用易乱;建议统一用 uv 管理项目运行依赖
9月2日的修改
现在的问题是数据是以内存列表的形式存在本地,这种方式相较于本地部署的向量数据库,存在以下的问题:
1. 数据持久性
内存列表:
数据完全存储在内存中,程序退出或服务器重启后数据会全部丢失,无法持久化保存。
适合临时数据处理或一次性任务,但无法用于需要长期存储的场景。本地 Chroma:
支持数据持久化到磁盘(默认存储在./chroma目录),即使服务重启,数据也不会丢失。
适合需要长期保存向量数据的场景,如知识库、历史对话存储等。
2. 检索能力
内存列表:
若要实现向量检索,需手动编写相似度计算逻辑(如余弦相似度),且只能进行线性扫描(遍历所有向量对比)。
当数据量较大(如超过 1 万条)时,检索速度会显著下降,效率极低。本地 Chroma:
内置高效的向量索引(如 HNSW 索引),支持近似最近邻(ANN)检索,可在海量数据中快速找到相似向量。
还支持按元数据过滤(如按文档来源、时间戳筛选),实现更精准的检索。
3. 数据管理
内存列表:
需手动维护数据结构(如增删改查逻辑),缺乏事务、并发控制等机制。
多线程 / 多进程访问时容易出现数据不一致,且难以实现批量操作。本地 Chroma:
提供完整的 CRUD API(创建、查询、更新、删除),支持批量操作和事务性处理。
内置并发控制,可安全处理多线程 / 多进程访问,适合复杂应用场景。
4. 扩展性
内存列表:
受限于单进程内存容量,数据量过大时可能导致内存溢出(OOM),且无法横向扩展。本地 Chroma:
虽然本地部署模式是单节点,但相比内存列表能更高效地管理磁盘上的大量数据。
若未来需要扩展,可迁移到 Chroma 的分布式部署模式(或兼容的集群方案)。
虽然代码里写了持久化存储方法和相似度计算逻辑,但是缺少高效的向量索引,并且存储和搜索的效率不如Chroma,所以今天的工作主要是用本地部署的Chroma替换掉原先的本地内存列表的存储
🚀 Chroma数据库使用指令
1. 启动服务器
cd /Data/wyh/dc-avatar-server
uv run python run_server.py2. RAG API 接口调用
获取统计信息:
curl -X GET http://localhost:12390/rag/stats搜索文档:
curl -X POST http://localhost:12390/rag/search \
-H 'Content-Type: application/json' \
-d '{"query": "你的查询内容", "top_k": 3}'添加文本:
curl -X POST http://localhost:12390/rag/add-text -H 'Content-Type: application/json' -d '{"text": "你要添加的文本内容"}'添加文件:
curl -X POST http://localhost:12393/rag/add-file -F "file=@你的文件路径.txt"清空数据库:
curl -X POST http://localhost:12390/rag/clear \
-H 'Content-Type: application/json' \
-d '{"confirm": true}'解决cursor的使用限制
"http.proxy": "http://127.0.0.1:33210", "http.proxyStrictSSL": false, "http.proxySupport": "override", "http.noProxy": 【】, "cursor.general.disableHttp2": true,